Last time in this series, I talked about latency and consistency models. I wanted to say more about the last of these, local perception filtering, but ended up running way past the word count I was shooting for. So I decided to split the post and turn that discussion into today’s topic.
Causality
Sharkey and Ryan justified local perception filters based on the limitations of human perception. In this post I will take a more physical approach derived from the causal theory of special relativity. For the sake of simplicity, we will restrict ourselves to games which meet the following criteria:
- The game exists within a flat space-time.
- All objects in the game are point-particles.
- All interactions are local.
- There is an upper bound on the speed of objects.
Many games meet these requirements. For example, in Realm of the Mad God, gameplay takes place in a flat 2D space. Objects like players or projectiles behave as point-masses moving about their center. Interactions only occur when two objects come within a finite distance of each other. And finally, no projectile, player or monster can move arbitrarily fast. The situation is pretty similar for most shooters and MMOs. But not all games fit this mold. As non-examples, consider any game with rigid body dynamics, non-local constraints or instant-hit weapons. While some of the results in this article may generalize to these games, doing so would require a more careful analysis.
Physical concepts
The basis for space-time consistency is the concept of causal precedence. But to say how this works, we need to recall some concepts from physics.
Let 


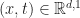
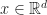
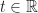

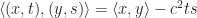
Using this bilinear form, vectors


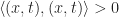
As a special consideration, we will say that a vector is causal if it is either time-like or null. We will suppose that time proceeds in the direction 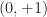
- Future-directed:
- Zero:
- Past-directed:

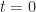
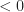
In the same way that a Euclidean is constructed from a normed vector space, space-time 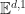
The relationship between these concepts can be visualized using a Minkowski diagram:
If you prefer a more interactive environment, Kristian Evensen made a browser based Minkowski diagram demo:
K. Evensen. (2009) “An interactive Minkowski diagram“
Space-time consistency
With the above physical language, we are now ready to define the space-time consistency as it applies to video games.
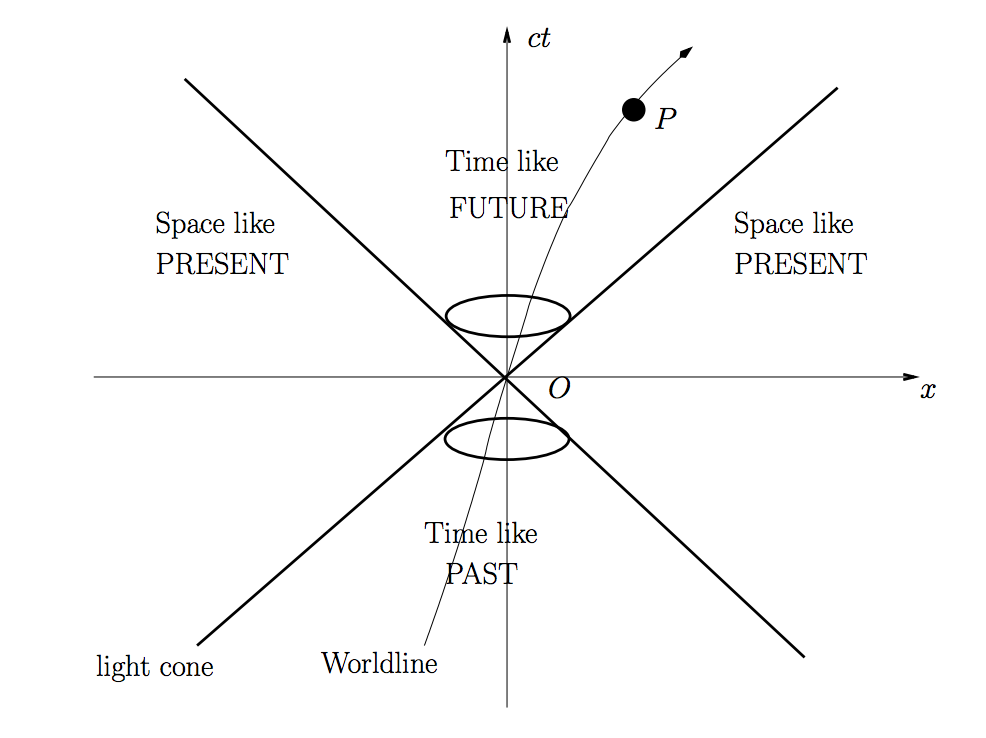
Given a pair of events,
we say that
causally precedes
(written
) if
is future-directed causal or zero.
Causal precedence is a partial order on the points of space-time, and it was observed by Zeeman to uniquely determine the topology and symmetry of space-time. (Note: These results were later extended by Stephen Hawking et al. to an arbitrary curved space-time, though based on our first assumption we will not need to consider such generalizations.) Causal precedence determines the following consistency model:
An ordered sequence of events
is space-time consistent if for all
,
.
Space-time consistency is a special case of causal consistency. Relativistic causal precedence is stricter than causality consistency, because it does not account for game specific constraints on interactions between objects. For example, a special effect might not influence any game objects, yet in a relativistic sense it causally precedes all events within its future light cone. Still space-time consistency is more flexible than strict temporal consistency, and as we shall see this can be exploited to reduce latency.
Cone of uncertainty
As a first application of space-time consistency, we derive a set of sufficient conditions for dead-reckoning to correctly predict a remote event. The basis for this analysis is the geometric concept of a light cone, which we now define:
Any closed regular set 
- Causal future:
- Causal past:

According to our assumptions about the direction of time, if an event had any causal influence on an event in 
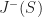

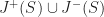
The causal future and past are idempotent operators,

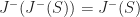
Sets which are closed under causal past/future are called closed causal sets. If

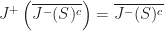
Now, to connect this back to dead-reckoning, let us suppose that there are two types of objects within the game:
- Active entities: Whose motion is controlled by non-deterministic inputs from a remote machine
- Passive entities: Whose trajectory is determined completely by its interactions with other entities.
For every active entity, we track an event 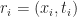
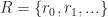
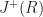
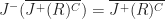
Here is a Minkowski diagram showing the how the cone of uncertainty evolves in a networked game as new remote events are processed:

Cauchy surfaces
In this section we consider the problem of turning a 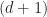
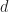
A hypersurface
This is not the only way to define a Cauchy surface. Equivalently,
Proposition 1: Any Cauchy surface
- The interior of the causal future:
- The interior of the causal past:
- And
If
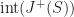
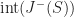
In a flat space-time, Cauchy surfaces can be parameterized by spatial coordinates. Let 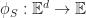

Then,
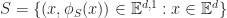
The inverse question of when a function 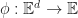
Theorem 1: A function
if and only if the subgradient of
is bounded by
.
Proof: To show that this condition is sufficient, it is enough to prove that any time parameterized time-like curve 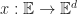
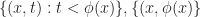


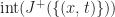
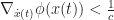
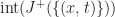
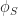
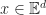
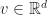

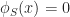

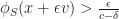
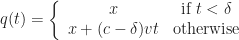
Consistency revisited
Rendering a game amounts to selecting a Cauchy surface and intersecting it with the world lines of all objects on the screen. The spatial coordinates of these intersections are then used to draw objects to the screen. From this perspective one can interpret a consistency model as determining a Cauchy surface. We now apply this insight to the three consistency models which were discussed last time.
Starting with strict consistency, define 
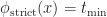
As we did with the cone of uncertainty, we can visualize the evolution of this Cauchy surface with a Minkowski diagram:

The same analysis applies to optimistic consistency. Let 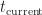
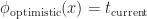
Which gives the following Minkowski diagram:

Unlike in the case of the strict consistency, the optimistic causal surface intersects the cone of uncertainty. As a result, it requires prediction to extrapolate the state of remote entities.
Finally, here is a Minkowski diagram showing the Cauchy surface of a local perception filter:

Time dilation
Local perception filters make finer geometric tradeoffs between local responsiveness and visual consistency. They achieve this by using a curved Cauchy surface. This has a number of advantages in terms of improving responsiveness, but introduces time dilation as a side effect. In a game, this time dilation will be perceived as a virtual acceleration applied to remote objects. To explain this concept, we need to make a distinction between local time and coordinate time. Coordinate time, 

Now suppose that we have a Cauchy surface, 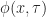
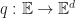
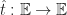
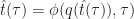
The time dilation observed in the particle is the ratio of change in coordinate time to change in local time, or by the chain rule,
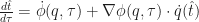
In general, we would like $\frac{d \hat{t}}{d \tau}$ to be as close to 1 as possible. If the time dilation factor ever becomes 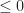
Theorem 2: If
and
, then for any time-like particle the time dilation is strictly positive.
The first condition is natural, since we can assume that the Cauchy surface is strictly moving forward in time. Similarly, according to Theorem 1 the second condition is the same as the requirement that
Intersecting world lines
Another tricky issue is finding the intersection of the world lines with the Cauchy surface. For special choices of world lines and Cauchy surfaces, it is possible to compute these intersections in closed form. For an example, in the original local perception filter paper Sharkey and Ryan carry out this analysis under the assumption that the world line for each particle is a polynomial curve. In general though it is necessary to use a numerical method to solve for the local time of each object. Fortunately, the requirements of space-time consistency ensure that this is not very expensive. Given a world line
Theorem 3: For any Cauchy surface
- If
, then for all
,
.
- If
, then for all
,
- There is only one
where
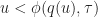
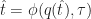
As a result, we can use bisection to find 
findWorldLineIntersection(phi, q, t0, t1, n):
for i=0 to n:
t = (t0 + t1) / 2
if t > phi(q(t)):
t1 = t
else:
t0 = t
return t0
This is exponential order convergence, and is about as fast as one can hope to achieve. Here phi is a function encoding the Cauchy surface as described above, q is coordinate time parameterized curve representing the world line of the particle, t0 and t1 are upper and lower bounds on the intersection region and n is the number of iterations to perform. Higher values of n will give more accurate results, and depending on the initial choice of t0 and t1, for floating point precision no more than 20 or so iterations should be necessary.
Limitations of local perception filters
While local perception filters give faster response times than strict surfaces, they do not always achieve as low a latency as is possible in optimistic prediction. The reason for this is that we do not allow the local perception filter to cross into the cone of uncertainty. If the local player passes into this region, then they will necessarily experience input lag.
We can quantify the situations where this happens. As a first observation, we note that the boundary of the cone of uncertainty is a Cauchy surface and so it can be described parametrically. That is define a function 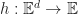

We will call 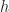
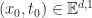
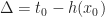
The magnitude of 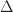
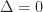
Theorem 4: If the round trip ping of each remote player is
and their last acknowledged position is
, then in order for a local perception filter to process a local input without lag, we must require that:
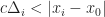
Under this interpretation, each remote player sweeps out a sphere of influence,

And if the local player passes into a sphere of influence they will experience lag which is proportional to their distance to the remote player. The size of these spheres of influence is determined by the ping of each remote player and the speed of light. As a result, players with a higher ping will inflict more lag over a larger region of space. Similarly, increasing the speed of light expands the spheres of influence for all players and can thus cause the local player to experience more input latency. So, the moral of this theorem is that if a game has a lot of close quarters combat or fast moving projectiles, then local perception filters might not be much help. On the other hand, if you can ensure that players are separated by at least 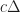
Software engineering issues
In general, it can be difficult to bolt networked replication on top of an existing game. The same is true of local perception filters. At minimum, a game engine must have the following features:
- Decoupled rendering
- Deterministic updates
- Persistence
Each of these capabilities requires architectural modifications. These changes are easy to implement if incorporated early in the design process, and so if networking is a priority then it pays to deal with them up front.
Decoupled rendering
Though this is standard practice today, it is especially important in a network game that the updates are not tied to rendered frames. Not only does this allow for fast and fluid animations regardless of the update rate, but it also makes games easier to debug by making time rate dependent behaviors deterministic. Glenn Fiedler popularized this idea in his writing on networked games:
G. Fiedler. (2006) “Fix your time step!“
That article covers the basics pretty well, though it glosses over the somewhat some subtle issues like input handling. In a fixed time step game it is more natural to use polling to handle inputs instead of asynchronous interrupts (ie events). In an environment like the DOM which defaults to the latter, it is necessary to enqueue events and process them within the main loop.
In some applications, like virtual reality, it may be important to respond to certain user inputs immediately. For example, the current position of the user’s head must be taken into account before rendering the latest frame or else the player will experience motion sickness. In this situation it is important that these inputs have a limited effect on the state of the game, or that their effects on the state can processed at a lower latency.
Adding local perception filters does not change the update step, but it does modify how the game is rendered. In psuedocode, this is what the drawFrame procedure might look like:
drawFrame(localTime):
phi = constructLocalPerceptionFilter(localTime)
x[] = rendered positions of all objects
for each object i:
x[i] = q[i](findWorldLineIntersection(phi,q[i],t0,t1,20))
drawObjects(x)
Deterministic updates
In order for a server to handle inputs from remote clients in any order, it is necessary that game updates are deterministic. That is, we require that given some list of events and a state, there is a function next that completely determines the successor state:
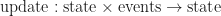
Deterministic updates also simplify testing a game, since it is possible to record and play back a sequence of events exactly. The cost though is that all system state including the value of each random number generator must be passed as input to the update function.
Persistence
Lastly, local perception filters need to maintain the history of the game. This representation should support efficient queries of the world lines of each object at arbitrary points in coordinate time and branching updates (since remote events can be processed out of order). As a sketch of how this can be implemented, refer to the following article by Forrest Smith:
F. Smith. (2013) “The Tech of Planetary Annihilation: ChronoCam“
At a high level, the ChronoCam system used by Planetary Annihilation gives a streaming persistent history all world lines in the game. In addition to being a necessary component in realizing local perception filters, Forrest Smith observes that maintaining a persistent history gives the following incidental benefits:
- Robust demo recordings – Since only positions are saved, demos are all upwards compatible and seeking/playback is very efficient
- Bandwidth savings – Fewer position updates can be sent to compensate for low capacity connections and paths can be simplified to save space
- Cheating prevention – The state of hidden units does not need to be replicated
The general problem of storing and maintaining the history of a system is known in data structures as “persistence“. In general, any data structure in the pointer-machine model with bounded in-degree can be made into a persistent version of the same data structure with only O(1) overhead. This transformation is described in the following paper:
J.R. Driscoll, N. Sarnak, D.D. Sleator, R.E. Tarjan. (1989) “Making data structures persistent” JCSS
While the DSST transformation is automatic, in practice it requires a certain amount of human finesse to apply correctly. One of the main sticking points is that bounded in-degree rules out certain classes of objects like iterators. Still, it is a useful idea and understanding it gives the basic tools necessary to implement persistent data structures.
Functional programming
Finally, I will conclude this section by observing that we can get all of the above features automatically if we use functional programming. For example, “deterministic” in the sense we are using it is just another word for functional purity. Similarly, data structure persistence is a weaker requirement than total immutability. Thus it stands to reason that if we took the more aggressive position and functionalized everything that we would get all the above features completely by accident. While I’m not sure how practical it is to write a game this way, it seems plausible that if functional programming becomes more popular, then local perception filters may see wider use within the game programming community.
A simplified shooter
To demonstrate these principles I made simple interactive demonstration. You can try it out here:
Demo!
One thing which I did not cover in detail was how to choose the Cauchy surface for the local perception filter in the first place. The main reason I didn’t bring this up was that the word count on this post had already spiraled out of control, and so I had to cut some material just to get it finished. I may revisit this topic in a later post and compare some different options.
In the demo, the local perception filter is implemented using the following function of the horizon:
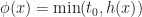
Where 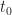
Conclusion
This post elaborates on the ideas sketched out by Sharkey and Ryan. In particular, we handle the problem of intersecting world lines with the Cauchy surface in general and give precise conditions on the geometry of the Cauchy surface for it to be jitter free. I think that this is the first time that anyone has proposed using a binary search to find the coordinate time for each world line intersection, though it is kind of an obvious idea in hindsight so I would not be surprised if it is already known. Additionally the precise interpretation of special relativity as applied to video games in this post is new, though the conceptual origin is again in Sharkey and Ryan’s paper.
In closing, local perception filters are a promising approach to latency hiding in networked games. Though they cannot eliminate lag in all cases, in games where most interactions are mediated by projectiles they can drastically reduce it. Understanding space-time consistency and local perception filtering is also helpful in general, and gives insight into the problems in networked games.
Next time
In the next post I want to move past latency and analyze the problem of bandwidth. It will probably be less mathematical than this post.





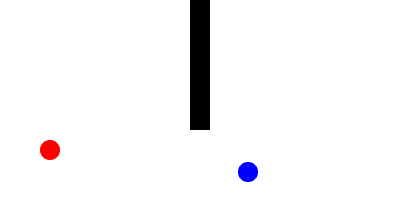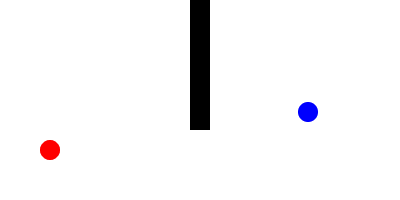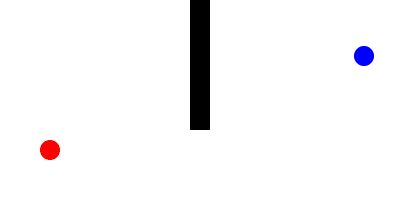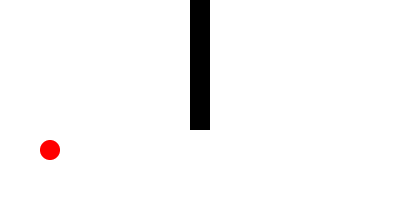



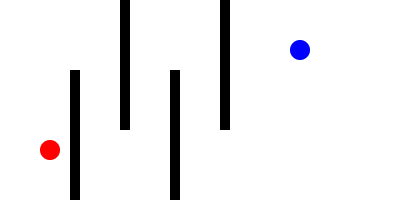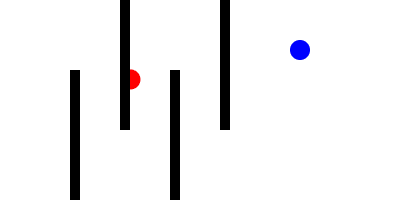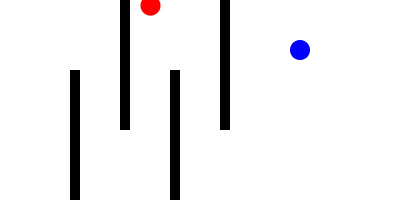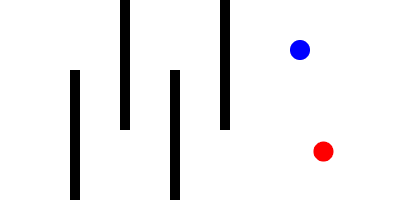


 be the total number of players,
be the total number of players, 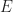 be the edges of a connected graph on
be the edges of a connected graph on  we assign a weight
we assign a weight 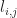 which is the latency of the edge in seconds. In the network we assume that players only communicate with those whom are adjacent in
which is the latency of the edge in seconds. In the network we assume that players only communicate with those whom are adjacent in 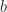 bits/second and that the size of the game state is
bits/second and that the size of the game state is  . Given these, we will now calculate the latency and bandwidth requirements of both active and passive replication under the optimal network topology with respect to minimizing latency.
. Given these, we will now calculate the latency and bandwidth requirements of both active and passive replication under the optimal network topology with respect to minimizing latency.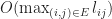 . The bandwidth required by active replication over a peer-to-peer network is
. The bandwidth required by active replication over a peer-to-peer network is 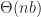 per client, since each client must broadcast to every other client, or
per client, since each client must broadcast to every other client, or 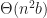 total.
total. . The total bandwidth consumed is
. The total bandwidth consumed is 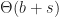 per client and
per client and  for the server.
for the server.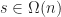 and if we make the additional reasonable assumption that
and if we make the additional reasonable assumption that 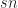 , then we could conclude that peer-to-peer replication is overall more efficient. However, in practice this is not quite true for several reasons. First, in passive replication it is not necessary to replicate the entire state each tick, which results in a lower total bandwidth cost. And second, it is possible for clients to eagerly process inputs locally thus lowering the perceived latency. When applied correctly, these optimizations combined with the fact that it is easier to secure a client-server network against cheating means that it is in practice a preferred option to peer-to-peer networking.
, then we could conclude that peer-to-peer replication is overall more efficient. However, in practice this is not quite true for several reasons. First, in passive replication it is not necessary to replicate the entire state each tick, which results in a lower total bandwidth cost. And second, it is possible for clients to eagerly process inputs locally thus lowering the perceived latency. When applied correctly, these optimizations combined with the fact that it is easier to secure a client-server network against cheating means that it is in practice a preferred option to peer-to-peer networking.