“Can we do to web services what Linux did to the operating systems?”
Imagine what the web with a P2P GitHub, a P2P YouTube, a P2P Twitter, a P2P Google search, and so on. But getting started with P2P services remains difficult, because:
“There is no P2P PostGRES!”
This is a very hard problem, so instead consider a more modest project:
“Let’s build a dynamic P2P ordered search index”
While pretty far from a full SQL database, a search index is a critical component for a modern RDBMS as it enables the following sorts of queries:
- Predecessor/successor
- Range search
- ORDER-BY
- Multi column joins
- …and much more
In this post we’ll talk about a few standard solutions to this problem, explain why they don’t work so well in P2P systems and finally we’ll present an idea that both simplifies these data structures and solves these problems.
Quick review: Merkle DAGs
For the uninitiated, building robust P2P systems seems like an impossible problem. How do you build anything if you can’t trust your peers? Well, cryptographers have known how to do this more than 60 years using a technique I’ll call Merkleization.
R. Merkle (1979) “A Certified digital signature“
Merkleization turns certain kinds of data structures into “invincible” P2P versions, and can be described in just 4 words:
Replace pointers with hashes
Merkleization is the active ingredient in BitTorrent, Git, IPFS and BitCoin‘s block chain. Using hashes we can validate any sequence of reads from a common data structure as long as we trust the root hash. This allows us to use any form of content addressable storage like a DHT or some other P2P network fetch arbitrary data, with no need to trust the network or storage layers. Such data structures can also work offline if the necessary data is cached locally. The worst case failure is that the data structure simply becomes temporarily unavailable if we can’t find a hash.
Because the objects in a Merkleized data structure are referenced using hashes, they are effectively immutable. These references must be created in causal order, and so they form a directed acyclc graph, hence the term Merkle DAG. All Merkle DAGs are functional data structures, and any functional data structure can be turned into a Merkle DAG by Merkleization. Updates to Merkle-DAGs can be performed using path-copying techniques as described in Okasaki’s PhD thesis:
C. Okasaki (1996) “Purely functional data structures” PhD Thesis
Merkle DAGs are an example of an authenticated data structure, which means that they support queries answered by untrusted 3rd parties. The trusted writer to the data structure only needs to provide the root hash to certify the correctness of sequences of queries from the reader. A more recent treatment of Merkle DAGs from the perspective of programming languages can be found here:
A. Miller, M. Hicks, J. Katz, E. Shi. (2014) “Authenticated data structures, generically” POPL
Merkle DAGs are pretty great, but they do have some limitations. The following general problems are universal to all functional data structures:
- Nodes are created in causal order, so no cycles are possible (ie no doubly linked lists)
- Changes by path copying are more expensive than in mutable data structures
- Objects are finite size. No O(1) RAM arrays (and no bucket sort, and so on)
- We have to deal with garbage collection somehow or else let objects slowly fill up storage… (Reference counting and freeing nodes induces side effects)
Still, they also get some cool benefits:
- Merkle DAGs are functionally persistent, we can easily rollback to old versions, fork them and even merge them efficiently
- Checking the equality of two Merkle DAGs is an O(1) operation — just compare their hashes!
- They’re authenticated (works with P2P)
- They’re simple!
B-trees
Now let’s return to ordered search indexes. A typical RDBMS would use some variation of a B-tree, and since B-trees don’t contain cycles we can Merkelize them, which has of course been done:
Y. Yang, D. Papadias, S. Papadopolous, P. Kalnis. (2009) “Authenticated Join Processing in Outsourced Databases” SIGMOD
However, it turns out that while B-trees are great in an imperative environment run on a trusted host, they are not ideal as a P2P functional data structure. One problem is B-tree implementations typically rely on amortized vacuuming/rebalancing in order to keep queries fast after many deletes, which can be expensive in a P2P setting. A second related issue is that the structure of a B-tree depends significantly on the order of insertion. Some databases implement mechanisms like “BULK INSERT” for sequentially inserting elements into a B-tree to avoid the performance degradation caused by many half-filled nodes.
Fundamentally, these problems are all aspects of a phenomenon I shall call hysteresis by analogy to systems theory:
Defn: A data structure for maintaining a dynamic ordered set of elements under insertion and removal has hysteresis if the history of updates determines the state of the data structure irrespective of the underlying set.
Data structures with hysteresis have path dependency, in the case of B-trees the actual tree structure depends on the order of inserts and removes. This means that B-trees are non-canonical, there is more than one way to encode any given sequence in a B-tree (ie there is extra information stored in the structure of the tree). This significantly limits what can be done to process indexes offline; for a B-tree you must reprocess all updates on the tree in the exact order of the writer to verify its computations. Finally, we can’t take full advantage of structure sharing to deduplicate common subsequences in trees or test the quality of two B-trees by comparing hashes. Of course, B-trees are not exceptional in this regard. Many other common search trees suffer from similar problems, including Red-Black trees, AVL-trees, Splay trees and so on.
Merkle Search trees
Fortunately, we can solve all the above problems at once if we can find some way to make the tree structure deterministic: that is any reordering of the same elements should produce the same data structure. It seems that deterministic authenticated search trees were first studied by Auvolat and Taïani:
A. Auvolat, F. Taïani. (2019) “Merkle Search Trees: Efficient State-Based CRDTs in Open Networks“
Merkle Search Trees are an incremental method for constructing determinstic B-trees. Their idea is to first hash all content which is inserted into the tree, and then to place items at a level proportional to the number of 0’s in the prefix of their hash written in base B. Under the assumption that all hashes are uniformly distributed, a Merkle search tree has the following properties:
- Every internal node has on average
children
- All leaves are on average the same distance from the root
- The tree is deterministic
Bottom up Chunking
Merkle search trees have some nice properties, but insertions and removal from them can be complex. Updates to a Merkle search tree proceed by traversing the tree top-to-bottom and locating an item based on its key and hash values. Instead we propose directly constructing trees from the bottom up, building up the tree layer-by-layer as chunked sorted lists of hashes. The data we are considering will always be arrays of 
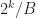
function nextChunk (hashes, start) {
for (let i = start; i < hashes.length; ++i) {
if (hashes[i] < pow(2, HASH_BITS) / B) {
return i;
}
}
return hashes.length;
}
This chunking procedure is similar to the content-defined chunking method used by the rsync backup system developed Tridgell in his PhD Thesis:
> A. Tridgell, (1999) “Efficient Algorithm for Sorting and Synchronization” PhD Thesis
Uniform distribution of hashes implies that the block sizes will follow a mean-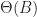
// assume items is a sorted array of (key, value) pairs
function createBTree (items) {
let hashes = items.map(storeLeaf);
do {
let nextHashes = []
for (let lo = 0; lo < hashes.length; ) {
// use the previous method to find the next chunk
let hi = nextChunk(hashes, lo);
nextHashes.push(storeNode(hashes.slice(lo, hi)));
lo = hi;
}
hashes = nextHashes;
} while (hashes.length !== 1)
return hashes[0];
}
Under the above assumptions, this should give a tree which is height at most 
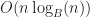


Even better, updates to these trees aren’t too expensive: In general, for any update/insert/delete operation, we first locate the block containing the elements we are modifying, then we rewrite those blocks as well as any nodes along its root-to-leaf path. Because of our chunking criteria, the extent of this modification changes no other nodes besides those along the root-to-leaf path, and so expected cost is 
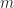
Conclusion
Merkle search trees are a promising direction for future investigations into peer-to-peer database indexes. Content chunking is generally applicable to many other types of search tree data structures, including for example R-trees and suffix arrays.
However, there remain some unsolved issues with both this approach and Merkle Search trees. A big problem is that neither are secure against adversarial inputs. A malicious writer could easily overflow a block with selected hashes, or inflate the tree height by brute forcing a prefix (though our bottom up construction is more resistant to this latter attack). Still this is a promising direction for peer-to-peer search indexes and suggests that scalable, fully authenticated functional databases may be possible in the future.
Acknowledgements
This project was supported by Protocol Labs LLC and jointly created with the help of Mikeal Rogers, who is the lead of the IPLD project at Protocol Labs.





























 , their Minkowski sum is defined as:
, their Minkowski sum is defined as: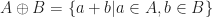
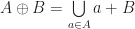
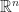 with an arbitrary group,
with an arbitrary group,  . If we do this, then we can define the Minkowski product over
. If we do this, then we can define the Minkowski product over 

