I just got back to the US after spending 3 months in Berlin, and I’ve now got plenty of ideas kicking around that I need to get on to paper. Recall that lately I’ve been blogging about solid modeling and in particular, we talked about meshing isosurfaces last time. However, in the examples from our previous discussion we only looked at some fairly small volumes. If our ultimate goal is to create something like Minecraft, where we use large volumetric objects to represent terrain, then we have to contend with the following difficult question:
How do we efficiently render large, dynamic, volumetric terrains?
One source of inspiration is to try generalizing from the 2D case. From the mid-90’s to the early 2000’s this was a hot topic in computer graphics, and many techniques were discovered, like the ROAM algorithm or Geometry Clipmaps. One thing that seems fundamental to all of these approaches is that they make use of the concept of level-of-detail, which is the idea that the complexity of geometry should scale inversely with the viewing distance. There at least a couple of good reasons why you might want to do this:
- Simplifying the geometry of distant objects can potentially speed up rendering by reducing the total number of vertices and faces which need to be processed.
- Also, rendering distant objects at a high resolution is likely to result in aliasing, which can be removed by filtering the objects before hand. This is the same principle behind mip-mapping, which is used to reduce artefacts in texture mapping distant objects.
Level of detail is a great concept in both theory and practice, and today it is applied almost everywhere. However, level of detail is more like a general design principle than an actual concrete algorithm. Before you can use it in a real program, you have to say what it means to simplify geometry in the first place. This motivates the following more specific question:
How do we simplify isosurfaces?
Unfortunately, there probably isn’t a single universal answer to the question of what it means to `simplify` a shape, but clearly some definitions are more useful than others. For example, you would hardly take me seriously if I just defined some geometry to be `simpler’ if it happened to be the output from some arbitrarily defined `simplification algorithm’ I cooked up. A more principled way to go about it is to define simplification as a type of optimization problem:
Given some input shape 

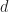
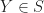
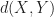

The intuition behind this is that we want to find a shape 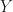
While there are as many different approaches to this problem as there are metrics, for the purposes of discussion we shall classify them into two broad categories:
- Surface: Metrics that operate on meshed isosurfaces.
- Volumetric: Metrics which operate directly on the sampled potential function.
I’ll eventually write a bit about both of these formulations, but today I’ll be focusing on the first one:
Surface Simplification
Of these two general approaches, by far the most effort has been spent on mesh simplification. There are a many high quality resources out there already, so I won’t waste much space talking about the basics here, and instead refer you to the following reference:
D. Luebke. (2001)”A Developer’s Survey of Mesh Simplification Algorithms” IEEE Computer Graphics and Applications.
Probably the most important class of metrics for surface simplification are the so-called quadratic error metrics. These approaches were described by Michael Garland and Paul Heckbert back in 1997:
M. Garland, P. Heckbert. (1997) “Surface Simplification Using Quadratic Error Metrics” SIGGRAPH 1997
Intuitively, quadratic error metrics measure the difference in the discrete curvature of two meshes locally. For piecewise linear meshes, this makes a lot of sense, because in flat regions you don’t need as many facets to represent the same shape. Quadratic error metrics work exceptionally well — both in theory and in practice — and are by far the dominant approach to mesh simplification. In fact, they have been so successful that they’ve basically eliminated all other competition, and now pretty much every approach to mesh simplification is formulated within this framework. Much of the work on mesh simplification today, instead focuses on the problem of implementing and optimizing. These technical difficulties are by no means trivial, and so what I will discuss here are some neat tricks that can help with simplifying isosurface meshes.
One particularly interesting paper that I’d like to point out is the following:
D. Attali, D. Cohen-Steiner, H. Edelsbrunner. (2005) “Extraction and Simplification of Iso-surfaces in Tandem” Eurographics Symposium on Geometry Processing.
This article was brought to my attention by Carlos Scheid in the comments on my last post. The general idea is that if you run your favorite mesh simplification algorithm in parallel while you do isosurface extraction, then you can avoid having to do simplification in one shot. This is a pretty neat general algorithm design principle: often it is much faster to execute an algorithm incrementally than it is to do it in one shot. In this case, the speed up ends up being on the order of 
I also learned of another neat reference from Miguel Cepero’s blog:
J. Wu, L. Kobbelt. (2002) “Fast Mesh Decimation by Multiple-Choice Techniques” VMV 2002
It describes an incredibly simple Monte-Carlo algorithm for simplifying meshes. The basic idea is that instead of using a priority queue to select the edge with least error, you just pick some constant number of edges (say 10) at random, then collapse the edge in this set with least error. It turns out that for sufficiently large meshes, this process converges to the optimal simplified mesh quite well. According to Miguel, it is also quite a bit faster than the standard heap/binary search tree implementation of progressive meshes. Of course Attali et al.’s incremental method should be even faster, but I still think this method deserves some special mention due to its extreme simplicity.
General purpose surface simplification is usually applied to smaller, discrete objects, like individual characters or static set pieces. Typically, you precalculate several simplified versions of each mesh and cache the results; then at run time, you just select an appropriate level of detail depending on the distance to the camera and draw that. This has the advantage that only a very small amount of work needs to be done each frame, and that it is quite efficient for smaller objects. Unfortunately, this technique does not work so well for larger objects like terrain. If an object spans many levels of detail, ideally you’d want to refine parts of it adaptively depending on the configuration viewer.
This more ambitious approach requires dynamically simplifying the mesh. The pioneering work in this problem is the following classic paper by Hugues Hoppe:
H. Hoppe. (1997) “View-dependent refinement of progressive meshes” ACM SIGGRAPH 1997
Theoretically, this type of approach sounds really great, but in practice it faces a large number of technical challenges. In particular, the nature of progressive meshing as a series of sequential edge collapses/refinements makes it difficult to compute in parallel, especially on a GPU. As far as I know, the current state of the art is still the following paper:
L. Hu, P. Sander, H. Hoppe. (2010) “Parallel View-Dependent Level-of-Detail Control” IEEE Trans. Vis. Comput. Graphics. 16(5)
The technology described in that document is quite impressive, but it has a several drawbacks that would prevent us from using it in volumetric terrain.
- The first point is that it requires some fairly advanced GPU features, like geometry shaders and hardware tesselation. This rules out a WebGL implementation, which is quite unfortunate.
- The second big problem is that even though it is by far the fastest known method for continuous view-dependent level of detail, it still is not quite good enough for real time game. If you have a per-frame budget of 16 ms total, you can’t afford to spend 22 ms just generating the geometry — and note that those are the times reported in the paper, taking into account amortization over multiple frames :(. Even if you throw in every optimization in the book, you are still looking at a huge amount of work per frame just to compute the level of detail.
- Another blocking issue is that this approach is does not work with dynamic geometry, since it requires a lot of precalculated edge collapses. While it might be theoretically possible to update these things incrementally, in practice it would probably require reworking this algorithm from scratch,.
- Finally, it also is not clear (at least to me) how one would adapt this type of method to deal with large, streaming, procedural worlds, like those in Minecraft. Large scale mesh simplification is by nature a global operation, and it is difficult to convert this into something that works well with paging or chunked data.
Next Time
Since this post has now grown to about 1700 words, I think I’ll break it off here. Next time we’ll look at volumetric isosurface simplification. This is a nice alternative to surface simplification, since it is a bit easier to implement view dependent level of detail. However, it has its own set of problems that we’ll soon discuss. I still haven’t found a solution to this problem which I am completely happy with. If anyone has some good references or tips on rendering large volumetric data sets, I’d be very interested to hear about it.
 by sampling it onto a cubical grid at some fixed resolution. To get intermediate values, we’ll just interpolate between grid points using the standard
by sampling it onto a cubical grid at some fixed resolution. To get intermediate values, we’ll just interpolate between grid points using the standard 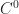 generalization of Minecraft-style voxel surfaces. Our goal in this article is to figure out how to extract a mesh of the implicit surface (or zero-crossings of
generalization of Minecraft-style voxel surfaces. Our goal in this article is to figure out how to extract a mesh of the implicit surface (or zero-crossings of 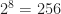 different possibilities, each of which is determined by the sign of the function at the 8 vertices of the cube:
different possibilities, each of which is determined by the sign of the function at the 8 vertices of the cube:
 cases, a number which can be further reduced to just 3 special cases by symmetry considerations. This is enough that you can work them out by hand.
cases, a number which can be further reduced to just 3 special cases by symmetry considerations. This is enough that you can work them out by hand.





















 volume plot of
volume plot of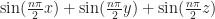
![[ - \frac{\pi}{2}, + \frac{\pi}{2} ]^3](https://s0.wp.com/latex.php?latex=%5B+-+%5Cfrac%7B%5Cpi%7D%7B2%7D%2C+%2B+%5Cfrac%7B%5Cpi%7D%7B2%7D+%5D%5E3&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . Here are the timings I got, measured in milliseconds
. Here are the timings I got, measured in milliseconds

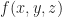 , it determines a set which we call the regularized 0-sublevel,
, it determines a set which we call the regularized 0-sublevel,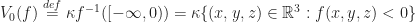
 to denote the
to denote the 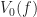 is the closure (of the preimage of (the open interval
is the closure (of the preimage of (the open interval 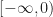 ) ). Our definition of
) ). Our definition of 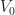 is a little bit different than the standard (but unfortunately slightly broken) definition which you see quite frequently:
is a little bit different than the standard (but unfortunately slightly broken) definition which you see quite frequently:![Z_0(f) \stackrel{def}{=} f^{-1}( [-\infty, 0] ) = \{ (x,y,z) \in \mathbb{R}^3 : f(x,y,z) \leq 0 \}](https://s0.wp.com/latex.php?latex=Z_0%28f%29+%5Cstackrel%7Bdef%7D%7B%3D%7D+f%5E%7B-1%7D%28+%5B-%5Cinfty%2C+0%5D+%29+%3D+%5C%7B+%28x%2Cy%2Cz%29+%5Cin+%5Cmathbb%7BR%7D%5E3+%3A+f%28x%2Cy%2Cz%29+%5Cleq+0+%5C%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
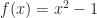 . This has a pair of roots at
. This has a pair of roots at 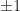 , and looks like this:
, and looks like this:
 and
and ![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) . Where things break down however is near the edge cases. If for example we took the function
. Where things break down however is near the edge cases. If for example we took the function 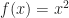 :
:
 is not necessarily a
is not necessarily a 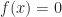
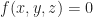
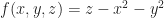
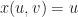
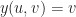

![\varphi : [0,1] \to \mathbb{R}^3](https://s0.wp.com/latex.php?latex=%5Cvarphi+%3A+%5B0%2C1%5D+%5Cto+%5Cmathbb%7BR%7D%5E3&bg=ffffff&fg=1a1a1a&s=0&c=20201002) , and then try to solve for the place where f composed with
, and then try to solve for the place where f composed with  crosses 0:
crosses 0: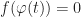
 .
.


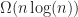 operations to perform a monotone subdivision, where
operations to perform a monotone subdivision, where  is the number of vertices.
is the number of vertices. algorithm out at the end of the day (where this
algorithm out at the end of the day (where this 








 .
.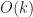 measures the algorithm dependent overhead which is determined by the complexity of the surface and the type of mesh generation. Since it is mesh generation that we want to study, ideally we’d like to keep
measures the algorithm dependent overhead which is determined by the complexity of the surface and the type of mesh generation. Since it is mesh generation that we want to study, ideally we’d like to keep 
 .
.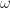 increases, the number of chambers increases as well, along with the surface area. This gives us a pretty good way to control for the complexity of surfaces in an experiment. I implemented this idea in a
increases, the number of chambers increases as well, along with the surface area. This gives us a pretty good way to control for the complexity of surfaces in an experiment. I implemented this idea in a 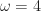 ). Garbage collection costs are amortized by repeated runs (10 in this case). All experiments were performed on a 65x65x65 volume with
). Garbage collection costs are amortized by repeated runs (10 in this case). All experiments were performed on a 65x65x65 volume with 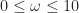 .
.