In a previous post, I talked a bit about solid modeling and discussed at a fairly high level what a solid object is. This time I’m going to talk in generalities about how one actually represent shapes in practice. My goal here is to say what these things are, and to introduce a bit of physical language which I think can be helpful when talking about these structures and their representations.
The parallel that I want to draw is that we should think of shape representations in much the same way that we think about coordinates. A choice of coordinate system does not change the underlying reality of the thing we are talking about, but it can reveal to us different aspects of the nature of whatever it is we are studying. Being conscious of the biases inherent in any particular point of view allows one to be more flexible when trying to solve some problem.
Two Types of Coordinates
I believe that there are two general ways to represent shapes: Eulerian and Lagrangian. I’ll explain what this all means shortly, but as a brief preview here is a small table which contrasts these two approaches:
| Eulerian | Lagrangian | |
| Coordinate System | Global/fixed | Local/moving |
| Modeling Paradigm | Implicit | Parametric |
| Transforms | Passive | Active |
Eulerian (Implicit)
The first of these methods, or the Eulerian representation, seeks to describe shapes in terms of the space they embedded in. That is shapes are described by maps from an ambient space into a classifying set:

More concretely, suppose we are working in n-dimensional Euclidean space 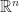



Again, if 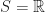
![S_0 = (-\infty, 0]](https://s0.wp.com/latex.php?latex=S_0+%3D+%28-%5Cinfty%2C+0%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

But these are of course somewhat arbitrary choices. We could for example replace 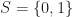

Which would be the set of all points in
Examples of Eulerian Representations
Motion in an Eulerian System
Say we have some Eulerian representation of our shape and we want to move it around. One simple way to think about this is that we have the shape and we simply apply some map 

I probably don’t need to convince you too much that motions are extremely useful in animation and physics, but they can also be a practical way to model shapes. In fact, one simple way to construct more complicated shapes from simpler ones is to deform them along some kind of motion. Now here is an important question:
Question: How do we apply a motion in an Eulerian coordinate system?
Or more formally, suppose that we have a set 


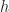

If you’ve never thought about this before, I encourage you to pause for a moment to think about it carefully.
Done? Ok, here is how we can arrive at the answer by pure algebraic manipulation. Starting with the definition for
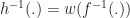
And taking inverses on both sides,

Which is of course only valid when 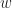
In an Eulerian coordinate system, to move a shape 
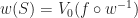
Or said another way:
Eulerian coordinate systems transform passively.
Pros and Cons
There are many advantages to an Eulerian coordinate system. For example, point wise operations like Boolean set operations are particularly easy to compute. (Just taking the min/max is sufficient to evaluate set intersection/union.) On the other hand, because Eulerian coordinates are passive, operations like rendering or projection (which are secretly a kind of motion) can be much more expensive, since they require solving an inverse problem. In general, this is as hard as root finding and so it is a non-trivial amount of work. In 3D, there is also the bigger problem of storage, where representations like voxels can consume an enormous amount of memory. However, in applications like image processing the advantages often outweigh the costs and so Eulerian representations are still widely used.
Lagrangian (Parametric)
Lagrangian coordinates are in many ways precisely the dual of Eulerian coordinates. Instead of representing a shape as a map from an ambient space to some set of labels, they instead map a parametric space into the ambient space:

The simplest example of a Lagrangian representation is a parametric curve, which typically acts by mapping an interval (like ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

But there are of course more sophisticated examples. Probably the most common place where people bump into Lagrangian coordinates is in the representation of triangulated meshes. A mesh is typically composed of two pieces of data:
- A cell complex (typically specified by the vertex-face incidence data)
- And an embedding fo the cell complex into
The embedding is commonly taken to be piecewise linear over each face. There are of course many examples of Lagrangian representations:
Examples of Lagrangian Representations:
Motion in Lagrangian Coordinates
Unlike in an Eulerian coordinate system, it is relatively easy to move an object in a Lagrangian system, since we can just apply a motion directly. To see why, let 

And so we conclude,
Lagrangian coordinate systems transform actively.
Pros and Cons
The main advantage to a Lagrangian formulation is that it is much more compact than the equivalent Eulerian form when the shape we are representing is lower dimensional than the ambient space. This is almost always the case in graphics, where curves and surfaces are of course lower dimension than 3-space itself. The other big advantage to Lagrangian coordinates is that they transform directly, which explains why they are much preferred in applications like 3D graphics.
On the other hand, Lagrangian coordinates are very bad at performing pointwise tests. There is also a more subtle problem of validity. While it is impossible to transform an Eulerian representation by a non-invertible transformation, this is quite easy to do in a Lagrangian coordinate system. As a result, shapes can become non-manifold or self-intersecting which may break certain invariants and cause algorithms to fail. This tends to make code that operates on Lagrangian systems much more complex than that which deals with Eulerian representations.


 .
.


 . Formally, it is defined to be the largest open set contained in
. Formally, it is defined to be the largest open set contained in 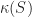 ), and the definition is basically what you think it is:
), and the definition is basically what you think it is: 
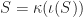

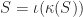
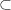 to a
to a  and
and 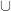 to a
to a 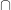 . I’ve heard it suggested that you
. I’ve heard it suggested that you  , is what we get when we subtract the interior from the closure:
, is what we get when we subtract the interior from the closure:

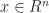 , choose any path
, choose any path ![p : [0,1] \to \mathbb{R}^n](https://s0.wp.com/latex.php?latex=p+%3A+%5B0%2C1%5D+%5Cto+%5Cmathbb%7BR%7D%5En&bg=ffffff&fg=1a1a1a&s=0&c=20201002) .
. crosses the boundary. If it is even, the point is outside; if it is odd the point is inside.
crosses the boundary. If it is even, the point is outside; if it is odd the point is inside.

