When I was younger I invested a lot of time into studying geometric algebra. Geometric algebra is a system where you can add, subtract and multiply oriented linear subspaces like lines and hyperplanes (cf. Grassmanian). These things are pretty important if you’re doing geometry, so it’s worth it to learn many ways to work with them. Geometric algebra emphasizes exterior products as a way to parameterize these primitives (cf. Plücker coordinates). Proponents claim that it’s simpler and more efficient than using “linear algebra”, but is this really the case?
In this blog post I want to dig into the much maligned linear algebra approach to geometry. Specifically we’ll see:
- Two ways to parameterize a linear subspace using matrices
- How to transform subspaces
- How to compute the intersection and span of any two subspaces
Encoding flats
A subspace of a vector space is a subset of vectors which are closed under scalar addition and multiplication. Geometrically they are points, lines and planes (which pass through the origin unless we use homogeneous coordinates). We can represent a k-dimensional subspace of an n-dimensional in two ways:
- As the span of a collection of k vectors.
- As the solution to a set of n – k linear equations.
These can be written using matrices:
- In the first case, we can interpret the span of k vectors as the image of an n-by-k matrix
- In the second, the solution of a set of n-k linear equations is another way of saying the kernel of an (n – k)-by-n matrix,
.
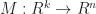
These two forms are dual to one another in the sense that taking the matrix transpose of one representation gives a different subspace, which happens to be it’s orthogonal complement.
Intersections and joins
The best parameterization depends on the application and the size of the flat under consideration. Stuff that’s easy to do in one form may be harder in the other and vice-versa. To get more specific, let’s consider the problem of intersecting and joining two subspaces.
If we have a pair of flats represented by systems of equations, then computing their intersection is trivial: just concatenate all the equations together. Similarly we can compute the smallest enclosing subspace of a set of subspaces which are all given by spans: again just concatenate them. And we can test if a subspace given by a span is contained in one given by equations by plugging in each of the basis vectors and checking that the result is contained in the kernel (ie maps to 0).
Linear transformations of flats
Depending on the form we pick flats transform differently. If we want to apply a linear transformation 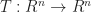
- If the flat is given by the image of a map,
, then we can just multiply by
- And if a flat is a system of equations, ie
, then we need to multiply by the inverse transpose of
.
The well known rule that normal vectors must transform by inverse transposes is a special case of the above.
Conversion
Finally we can convert between these two forms, but it takes a bit of work. For example, finding the line determined by the intersection of two planes through the origin in 3D is equivalent to solving a 2×2 linear system. In the general case one can use Gaussian elimination.
Is this less intuitive?
I don’t really know. At this point I’m too far gone to learn something else, but it’s much easier for me to keep these two ideas in my head and just grind through some the same basic matrix algorithm over and over than to work with all the specialized geometric algebra terms. Converting things into exterior forms and plucker coordinates always seems to slow me down with extra details (is this a vee product, inner product, circle, etc.), but maybe it works for some people.
 is a subset of
is a subset of  . A tuple of n elements,
. A tuple of n elements,  is related (under R) if and only if,
is related (under R) if and only if,

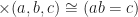

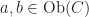 set of morphisms,
set of morphisms, 
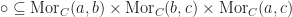 for every triple of objects
for every triple of objects 
 is a functional relation,
is a functional relation, 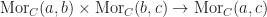
 such that
such that 


