The last post I wrote on Minecraft-like engines got a lot of attention, and so I figured it might be interesting to write a follow up. This time I’ll try to tackle a different problem:
Meshing
One of the main innovations in Infiniminer (and Minecraft) is that they use polygons instead of raycasting to render their volumes. The main challenge in using polygons is figuring out how to convert the voxels into polygons efficiently. This process is called meshing, and in this post I’m going to discuss three different algorithms for solving this problem. But before doing this, we first need to say a bit more precisely what exactly meshing is (in the context of Minecraft maps) and what it means to do meshing well. For the sake of exposition, we’ll consider meshing in a very simplified setting:
- Instead of having multiple block types with different textures and lighting conditions, we’ll suppose that our world is just a binary 0-1 voxel map.
- Similarly we won’t make any assumptions about the position of the camera, nor will we consider any level of detail type optimizations.
- Finally, we shall suppose that our chunks are stored naively in a flat bitmap (array).
I hope you are convinced that making these assumptions does not appreciably change the core of the meshing problem (and if not, well I’ll try to sketch out in the conclusion how the naive version of these algorithms could be extended to handle these special cases.)
In a typical Minecraft game chunks do not get modified that often compared to how frequently they are drawn. As a result, it is quite sensible to cache the results from a mesher and only ever call it when the geometry changes. Thus, over the lifetime of a mesh, the total amount of computational work it consumes is asymptotically dominated by the cost of rendering.
Recall that at a high level polygon rendering breaks down into two parts: 1.) primitive assembly, and 2.) scan conversion (aka polygon filling). In general, there really isn’t any way to change the number of pixels/fragments which need to be drawn without changing either the resolution, framerate or scene geometry; and so for the purposes of rendering we can regard this as a fixed cost (this is our second assumption). That leaves primitive assembly, and the cost of this operation is strictly a function of the number of faces and vertices in the mesh. The only way this cost can be reduced is by reducing the total number of polygons in the mesh, and so we make the following blanket statement about Minecraft meshes:
Criteria 1: Smaller meshes are better meshes.
Of course, the above analysis is at least a little naive. While it is true that chunk updates are rare, when they do happen we would like to respond to them quickly. It would be unacceptable to wait for more than a frame or two to update the displayed geometry in response to some user change. Therefore, we come to our second (and final) criteria for assessing mesh algorithms:
Criteria 2: The latency of meshing cannot be too high.
Speed vs. Quality
Intuitively, it seems like there should be some tradeoff here. One could imagine a super-mesher that does a big brute force search for the best mesh compared to a faster, but dumber method that generates a suboptimal mesh. Supposing that we were given two such algorithms, it is not a-priori clear which method we should prefer. Over the long term, maybe we would end up getting a better FPS with the sophisticated method, while in the short term the dumb algorithm might be more responsive (but we’d pay for it down the road).
Fortunately, there is a simple solution to this impasse. If we have a fast, but dumb, mesher; we can just run that on any meshes that have changed recently, and mark the geometry that changed for remeshing later on. Then, when we have some idle cycles (or alternatively in another thread) we can run the better mesher on them at some later point. Once the high quality mesh is built, the low quality mesh can then be replaced. In this way, one could conceivably achieve the best of both worlds.
Some Meshing Algorithms
The conclusion of this digression is that of the two of these criteria, it is item 1 which is ultimately the most important (and unfortunately also the most difficult) to address. Thus our main focus in the analysis of meshing algorithms will be on how many quads they spit out. So with the preliminaries settles, let’s investigate some possible approaches:
The Stupid Method:
The absolute dumbest way to generate a Minecraft mesh is to just iterate over each voxel and generate one 6-sided cube per solid voxel. For example, here is the mesh you would get using this approach on a 8x8x8 solid region:
 The time complexity of this method is linear in the number of voxels. Similarly, the number of quads used is 6 * number of filled voxels. For example, in this case the number of quads in the mesh is 8*8*8*6 = 3072. Clearly this is pretty terrible, and not something you would ever want to do. In a moment, we’ll see several easy ways to improve on this, though it is perhaps worth noting that for suitably small geometries it can actually be workable.
The time complexity of this method is linear in the number of voxels. Similarly, the number of quads used is 6 * number of filled voxels. For example, in this case the number of quads in the mesh is 8*8*8*6 = 3072. Clearly this is pretty terrible, and not something you would ever want to do. In a moment, we’ll see several easy ways to improve on this, though it is perhaps worth noting that for suitably small geometries it can actually be workable.
The only thing good about this approach is that it is almost impossible to screw up. For example, I was able to code it up correctly in minutes and it worked the first time (compared to the culling method which took me a few iterations to get the edge cases right.) Even if you don’t plan on using this approach it can still be handy to have it around as a reference implementation for debugging other algorithms.
Culling:
Clearly the above method is pretty bad. One obvious improvement is to just cull out the interior faces, leaving only quads on the surface. For example, here is the mesh you get from culling the same 8x8x8 solid cube:

Practically speaking, this method is pretty much the same as the previous, except we have to do a bit of extra book keeping when we traverse the volume. The reason for this is that now we not only have to read each voxel, but we we also have to scan through their neighbors. This requires a little more thought when coding, but time complexity-wise the cost of generating this mesh is asymptotically the same as before. The real improvement comes in the reduction of quads. Unlike the stupid method, which generates a number of quads proportional to the boundary, culling produces quads proportional to the surface area. In this case, the total number of faces generated is 8*8*6 = 384 — a factor of 8x better!
It is not hard to see that the culled mesh is strictly smaller than the stupid mesh (and often by quite a lot!). We can try to estimate how much smaller using a dimensional analysis argument: assuming that our geometry is more-or-less spherical, let 
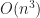
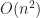

Greedy Meshing:
The previous two approaches are probably the most frequently cited methods for generating Minecraft-like meshes, but they are quite far from optimal. The last method that I will talk about today is a greedy algorithm which merges adjacent quads together into larger regions to reduce the total size of the geometry. For example, we could try to mesh the previous cube by fusing all the faces along each side together:

This gives a mesh with only 6 quads (which is actually optimal in this case!) Clearly this improvement by a factor of 64 is quite significant. To explain how this works, we need to use two ideas. First, observe that that it suffices to consider only the problem of generating a quad mesh for some 2D cross section. That is we can just sweep the volume across once in each direction and mesh each cross section separately:

This reduces the 3D problem to 2D. The next step (and the hard one!) is to figure out how to mesh each of these 2D slices. Doing this optimally (that is with the fewest quads) is quite hard. So instead, let’s reformulate the problem as a different type of optimization. The idea is that we are going to define some type of total order on the set of all possible quadrangulations, and then pick the minimal element of this set as our mesh. To do this, we will first define an order on each quad, which we will then extend to an order on the set of all meshes. One simple way to order two quads is to sort them top-to-bottom, left-to-right and then compare by their length.
More formally, let’s denote a quad by a tuple 
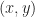
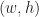
![Q_{x,y,w,h} = \{ (s,t) \in \mathbb{R}^2 : x \leq s \leq x + w \: \mathrm{ and } \: y \leq t \leq y+h \} = [x,x+w] \times [y,y+h]](https://s0.wp.com/latex.php?latex=Q_%7Bx%2Cy%2Cw%2Ch%7D+%3D+%5C%7B+%28s%2Ct%29+%5Cin+%5Cmathbb%7BR%7D%5E2+%3A+x+%5Cleq+s+%5Cleq+x+%2B+w+%5C%3A+%5Cmathrm%7B+and+%7D+%5C%3A+y+%5Cleq+t+%5Cleq+y%2Bh+%5C%7D+%3D+%5Bx%2Cx%2Bw%5D+%5Ctimes+%5By%2Cy%2Bh%5D+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
By a 2D quad mesh, here we mean a partition of some set 
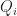
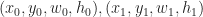
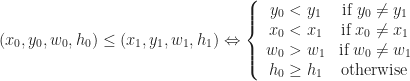
Or if you prefer to read psuedocode, we could write it like this:
compareQuads( (x0, y0, w0, h0), (x1, y1, w1, h1) ):
if ( y0 != y1 ) return y0 < y1
if ( x0 != x1 ) return x0 < x1
if ( w0 != w1 ) return w0 > w1
return h0 >= h1
Exercise: Check that this is in fact a total order.
The next thing we want to do is extend this ordering on quads to an ordering on meshes, and we do this in a very simple way. Given two sorted sequences of quads 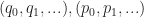
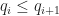
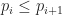

You may be skeptical that finding the least element in this new order always produces a better quad mesh. For example, there is no guarantee that the least element in this new order is also the mesh with the fewest quads. Consider what you might get when quad meshing a T-shape using this method:

Exercise 2: Find a mesh of this shape which uses fewer quads.
However, we can say a few things. For example, it always true that each quad in the greedy mesh completely covers at least one edge on the perimeter of the region. Therefore, we can prove the following:
Proposition: The number of quads in the greedy mesh is strictly less than the number of edges in the perimter of the region.
This means that in the worst case, we should expect the size of the greedy mesh to be roughly proportional to the number of edges. By a heuristic/dimensional analysis, it would be reasonable to estimate that the greedy mesh is typically about 
Theorem: The greedy mesh has no more than 8x as many quads than the optimal mesh.
That’s within a constant factor of optimality! To prove this, we’ll need to introduce a bit of nomenclature first. We’ll call a vertex on the perimeter of a region convex if it turns to the right when walking around the mesh clockwise, and otherwise we’ll call it concave. Here is a picture, with the convex vertices colored in red and the concave vertices colored in green:

There’s a neat fact about these numbers. It turns out that if you sum them up, you always get the same thing:
Proposition: For any simply connected region with 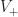
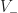
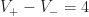
This can be proven using the winding number theorem from calculus. But we’re going to apply this theorem to get a lower bound on the number of quads in an arbitrary mesh:
Lemma: Any connected genus 
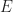
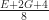
Proof: Let 


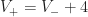
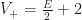
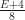
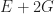

To prove our main theorem, we just combine these two lemmas together, using the fact that 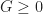
Optimal 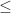 Greedy Culled Stupid
Greedy Culled Stupid
So now that I’ve hopefully convinced you that there are some good theoretical reasons why greedy meshing outperforms more naive methods, I’ll try to say a few words about how you would go about implementing it. The idea (as in all greedy algorithms) is to grow the mesh by making locally optimal decisions. To do this, we start from an empty mesh and the find the quad which comes lexicographically first. Once we’ve located this, we remove it from the region and continue. When the region is empty, we’re done! The complexity of this method is again linear in the size of the volume, though in practice it is a bit more expensive since we end up doing multiple passes. If you are the type who understands code better than prose, you can take a look at this javascript implementation which goes through all the details.
Demo and Experiments
To try out some of these different methods, I put together a quick little three.js demo that you can run in your browser:
Click here to try out the Javascript demo!
Here are some pictures comparing naive meshing with the greedy alternative:


Naive (left), 690 quads vs. Greedy (right), 22 quads


4770 quads vs. 2100 quads
.

2198 quads vs. 1670 quads
As you can see, greedy meshing strictly outperforms naive meshing despite taking asymptotically the same amount of time. However, the performance gets worse as the curvature and number of components of the data increase. This is because the number of edges in each slice increases. In the extreme case, for a collection of disconnected singleton cubes, they are identical (and optimal).
Conclusion and some conjectures:
Well, that’s it for now. Of course this is only the simplest version of meshing in a Minecraft game, and in practice you’d want to deal with textures, ambient occlusion and so on (which adds a lot of coding headaches, but not much which is too surprising). Also I would ask the reader to excuse the fairly rough complexity analysis here. I’d actually conjecture that the true approximation factor for the greedy algorithm much less than 8, but I’ve spent enough time writing this post so I guess I’ll just leave it as is for now. I think the real weakness in my analysis lies in the computation of the upper bound on the size of greedy mesh. I’d actually guess the following is true:
Conjecture: The size of the greedy mesh is at most 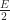
If this conjecture holds true, then it would reduce the current bounds on the approximation factor to 4x instead of 8x. It’s also not clear that this is the best known greedy approximation. I’d be interested to learn how Minecraft and other voxel engines out there solve this problem. From my time playing the game, I got the impression that Minecraft was doing some form of mesh optimization beyond naive culling, though it was not clear to me exactly what was going on (maybe they’re already doing some form greedy meshing?)
It is also worth pointing out that the time complexity of each of these algorithms is optimal (ie linear) for a voxel world which is encoded as a bitmap. However, it would be interesting to investigate using some other type of data structure. In the previous post, I talked about using run-length encoding as an alternative in-memory storage of voxels. But greedy meshing seems to suggest that we could do much better: why not store the voxels themselves as a 3D cuboid mesh? Doing this could drastically reduce the amount of memory, and it is plausible that such a representation could also be used to speed up meshing substantially. Of course the additional complexity associated with implementing something like this is likely to be quite high. I’ll now end this blog post with the following open problem:
Open Problem: Do there exist efficient data structures for dynamically maintaining greedy meshes?
If you have other questions or comments, please post a response or send me an email!
Errata
6/30/12: Corrected an error in the definition of the order on each quad. Was written (x,y,w,h) when it should have been (y,x,w,h) (Thanks Matt!)

Counterexample for your conjecture:
(Assuming that x is horizontal and increasing right, and y is vertical increasing down.)
I suspect, though, that every time you subtract the next greedy quad from the current figure, you reduce (horizontal edges) + (total genus) – (connected components) by at least 1.
Hi Matt! Thanks for the reply!
Unfortunately, that example doesn’t quite work. The right-most quad second from the top is not lexicographically minimal (the bottom part could be extended). I added your test case to the demo to show why, though here is a picture to show what goes wrong:
It’s still neat to note though that this hits the extreme bound for the conjecture of having exactly E/2 quad. If it had just one more quad it would be a valid counter example.
This might be a valid counterexample: https://imgur.com/l0MNtE1
With 10 quads and 16 edges, this would go beyond the bound of E/2.
We’re placing that third rectangle differently… I think your coordinates are oriented differently than mine. As a quick check, try flipping that example over, and rotating it.
Perhaps there is a communication error… Here’s the same mesh in the 3 other quarter rotations:
Ah, I think I see it. I think you’re using the sort-of-lexicographic ordering over (y,x,w,h), instead of over (x,y,w,h). If that’s true, a different counterexample works: in your first rotation, above, remove the block under the top-left corner.
If that’s not right, then I’m just not sure what’s going on…
Ah! You’re right. I made a mistake when I was writing it up. I should’ve sent you a copy to proof read first 😛 I’m still not sure what you mean by that counter example though. But at least this explains where I messed up! I’m going to go fix the article right now. Hopefully there aren’t too many more mistakes hiding in there!
Sounds like you’re only considering non-overlapping quads. There are certainly situations where overlapping quads can reduce your quad count (eg the X pentomino). Is this because it makes the problem more complicated, or because there are other problems with overlapping quads?
Hi Christopher,
I have indeed thought about it. While it is true that grouping occluded quads could reduce the face count, in practice it does have some drawbacks, the most noticeable of which is that it could drastically increase the amount of overdraw. I’m not really sure if it would be a net benefit or cost, but my gut tells me that it would probably be the latter. If you ever try it, let me know what your results are! (I’d be happy to have my intuition proven wrong.)
I’d be interested in how to implement the greedy meshing with different types of voxels. For instance, red, green and blue voxels, or multiple voxel textures. I had an implementation, but it took a lot of time and processing power compared to yours.
By the way, I’ve modded Minecraft to see in a wireframe view with OpenGL, and they don’t use greedy meshing; only naïve culling. However, I suspect this could have some efficiency boost over greedy meshing for world modification, in that they don’t remesh the whole chunk for each block modification (maybe they do, but I can’t confirm). Say you break a voxel: an efficient way to handle the change would be to remove the vertices and indices associated with that voxel and add vertices and indices associated with the neighbouring voxels.
Your implementations do not consider clockwise or counter-clockwise culling for the faces, which is needed for any practical use.
Also, the greedy mesh seems to fail in some cases in the noise example.
Hi Lazlo,
Thank you for your comments! It’s true the implementation does not consider normal direction, but I said up front that this would be one of the simplifying assumptions. It isn’t too difficult to modify the code deal with either multiple block types or different normal directions. What you would do is modify the array called “mask” in the code to store an integer value which encodes the type of each block. You’d need at least 1 bit for orientation, and then you could use the rest to store block color or whatever. Then when you build the greedy quad, you store the type of the block you are scanning over and only group blocks which are the same type together. I don’t think it should be too difficult to modify the code to handle these situations. If there is enough demand I could put together another demo showing how this works (for 3 block types for example.)
What I am more concerned about is the possibility that there might be a bug in the code. Can you take a screen shot of a situation where it fails? I’ve not found any bugs in my testing, but if you could show me where things go wrong I might be able to fix it.
Sure, here it is: http://i.imgur.com/nlflz.png
As you can see, some quads that should merge do not.
Ah, I see what’s going on. It is merging faces without regard to the normal direction. This is actually what it is supposed to do, though the effect is a bit unintuitive. If you look at the other side of that cube, you’ll see that it shares a common face with the one facing toward the camera from this perspective. A good example of this type of behavior is in the `checker’ test case, where the greedy implementation merges all the quads along each strip, even though their orientations are different. For the moment, I’d consider this intended behavior, but if you wanted to fix it, the way to go would be to group quads into different types depending on their normals.
Considering that many GPUs internally remap quads to triangle pairs anyway, wouldn’t it be preferable to skip straight to Delaunay triangulation?
That’s a pretty good idea! Though I think a Delaunay triangulation is probably not quite the right thing to do. I believe you are really thinking of this problem:
http://en.wikipedia.org/wiki/Polygon_triangulation
The most standard way to do polygon triangulation is to perform a monotone subdivision of the volume, then triangulate that. Unfortunately, this would end up being slower than the method in the article; but perhaps the meshes would be small enough that you still gain some advantage. Unfortunately, polygon triangulation can be quite difficult. For example, the only known O(n) algorithm for triangulating a simple polygon is due to Chazelle — and it is so complicated that it has never been successfully implemented! (This fact is a long standing joke amongst computational geometers.) For a general polygon with holes, it is also known that you can’t do any faster than Omega(n log(n)).
But then again, these polygons we are dealing with are not general simple polygons, and I would not be surprised if there are much simpler ways to do things in the case of Minecraft. It is certainly something interesting to think about.
How could I add some smoothness to the mesh, other than tessellating the mesh after the generation? I’m aiming for something like smoothly curved mountain ladders, but perhaps this is a much more difficult problem to solve.
Hi Alejandro,
I am glad you asked this question! I am currently working on a post describing how to deal with smooth surfaces. I will hopefully have it ready and posted shortly!
I may be wrong but shouldn’t the inequality be y <= t <= y + h rather than just h?
Good catch! Fixed.
I’m finding the greedy mesh part a bit hard to follow without some sample code.
There is some sample code in the demo. If you do “View page source” you can see it. Alternatively, it is also on my github page: https://github.com/mikolalysenko/mikolalysenko.github.com
I haven’t worked with OpenGL / DirectX recently, but if I remember correctly smaller quads are preferable because the lightning is only calculated on the vertices and interpolated between them. Therefore filling everything with one big quad might be a really bad solution even if it reduces the number of vertices.
That is why you would only merge two quads if the lighting values at their vertices are the same. The same argument applies to why you wouldn’t merge two quads if they had different textures or other shading parameters.
On the sphere example (with your javascript demo), I’m finding that culled results in faster average framerate than when using the greedy algorithm… How can this be?
Setup: MacBook Pro 2.4 Ghz Core i5, NVIDIA GeForce GT 330M 256MB.
Most likely an issue with three.js’ software renderer. These models are all so small that differences in rendering time should be inconsequential (with the possible exception of the stupid meshers).
Well, this brings up an interesting issue then. If the difference isn’t noticeable in practice, is it worth the extra effort?
Is there an example where it is noticeable?
There is a big difference on large terrains with many voxels. To back this up, here are some references to other people who have tried out this technique in their own projects:
http://www.sea-of-memes.com/LetsCode66/LetsCode66.html
If you are just going to render a single chunk of maybe 32x32x32 voxels using a silly 2d canvas hack, it honestly doesn’t matter what you do performance wise. Also I wouldn’t take the small variations in three.js’ canvas based rendering too seriously. That code is probably not well optimized to draw large facets, though on a real GPU this would not be an issue. Anyway, the code on this page is meant to demonstrate the concepts, not provide a complete voxel engine.
Thank you mikolalysenko for sharing that. 🙂
have you considered using octrees? Also I have a question how would you go about smooth the textures a bit similar to how cube world looks. Is it just a texture? here is a link to picture. http://wollay.blogspot.com/search?updated-max=2011-06-15T23:28:00-07:00&max-results=7&reverse-paginate=true. Is there also a shader library? Thanks for the awesome work!
Great stuff! Late to the party as usual but have a question. In culling mode, you seem to leave many identical vertices, is there a reason for that? E.g. two visible adjecant blocks share 4 identical vertices which are counted and used separately. Is there any way you can check on the fly if vertex has been defined already, and just use old one for new quad if it has? Or maybe run over all of them afterwards and remove all the doubles and update quads? Or are those duplicate vertices needed to carry different normals or something else? Thanks!
I have noticed that Minecraft seems to use advanced meshing, I have seen holes that were not rendered, and they allowed me to see into the mesh, and I have watched the world load when I am moving faster than the world generator and mesher can keep up. I noticed that entities, torches, Xycraft quartz crystals (which are everywhere), lava (which may have it’s own mesher) etc are rendered weather you should be able to see them or not, along with some of the block faces that are adjacent to them. Such blocks are probably exempt because they are animated, so large amounts of entities and machines can and will impact the FPS minecraft runs at, and it explains why certain mods (like Xycraft) seem to have such a large impact on FPS.
Quartz crystals are animated all the time, and they are scattered randomly throughout the chunk in areas not filled with air, they are basically the checkerboard pattern that is impossible to optimize, unless the mesher is told to cull any entities that are not in sight without preventing them from operating. Entities pose a serious problem for any mesher more complex than the stupid one.
A potentially viable method for storing chunks as a 3d mesh that would handle entities fairly well would basically store the world as two or more layers, each layer would be three dimensional, and would be used for a different type of block (where type refers to regular, entity, liquid, etc). All of the layers would occupy the same 3D space, and to improve the resource efficiency of the mesher, each layer would have a priority level, and would be handled in a different way.
The reason for three different meshes is to prevent the mesher from having to re-mesh the entire chunk every time you place an entity, or come across a flowing liquid block.
The priority system is used to determine how “air” blocks are handled, the non air blocks in each layer can overwrite air blocks in any layer of lower priority.
EX:
layer priority: entity, liquid, regular
The first layer would contain regular blocks, and all non-regular blocks as air, and then the greedy mesher would be used to simplify the mesh as much as possible so it would take the least amount of memory and GPU power.
The second layer would contain liquids and air, where air is all non-liquid blocks, the greedy mesher would do the same thing it did with the regular blocks, except this time the entire mesh would be rendered if any part of it was in sight to prevent the computer from re-meshing that part of the chunk every time a new block came into sight. Also, most pools of liquid blocks are fairly easy to render because they are often times a flat surfaces.
The third layer would contain entities, and it wouldn’t even try to simplify the mesh, it would simply store each entity as an (x,y,z) co-ordinate triple. it would decide weather or not each entity would be rendered based if the entity had regular blocks between it and the camera. all of the entities would be active (but not necessarily rendered) while the chunk is loaded.
The stupid mesher would handle any recent modifications to each layer while the chunk is being watched, the greedy mesher would be used while the chunk is not being watched, or if it hasn’t undergone any modifications for a set period of time. The meshers would not attempt to keep up with the entity modifications, those would be done using unique data values and co-ordinate triples because many entities can spawn massive amounts of mini-entities/particles, and several entities can occupy the same space as other entities, and mobile entities require far more precise location data that would greatly degrade the speed and efficency of the meshers if they tried to deal with it.
“The idea is that we are going to define some type of total order on the set of all possible quadrangulations”
You explain very well how to define total order and sort quadrangulations. But … how do you obtain these “all possible quadrangulations ?” Because I remember you that initially we have only a bunch of voxel face (quadrangulation) of same size placed together
An optimisation for meshing-after-a-change could be:
LOD 0: Use a very weak optimisation which only joins 2 rectangles which share an edge.
LOD 1: Cull stuff which is not visible (any angle) from the outside.
LOD 2: Cull stuff which relys on vision through areas which are hidden by neighbouring chunks.
…
I’d love to see this in action (chunks maybe 16^3).
NOTE: The one thing I jet don’t understand are the rendering steps required for various textures, lighting, reflection, …, but 0/1 block exists is sufficient to understand meshing I think.
Hi, I’ve ported your code to c++ and got it working. But how do I count the number of triangles to be drawn because I have to use this function glDrawArrays(GL_TRIANGLES, 0, numberOfTriangles) ?
Hello!
Is your greedy algorithm free to use in my project if I did commercial?
Yep!
This is really fantastic stuff Mikola. How you suggest knowing the normal direction using the “Culling Method”?
hi!Have you read this one? MeshLab still use it today to do general mesh simplification.
Surface Simplification Using Quadric Error Metrics
Crazy late here i know ! but I’ve got to reply.
This is an awesome subject and i really appreciate your treatment !
By combining greedy meshing with dynamic texture generation and packing you would completely remove all constrains regarding merge limitation such as texture type and lighting values.
Further as to your discussion in the comments – while allowing those trivial overlaps provides minimal polygon savings, by combining that technique with the aforementioned dynamic texture system you can introduce the concept of alpha occlusion to provide extreme savings – asymptotically as you allow for more alpha the cost becomes unrelated to the volume of the area being meshes and instead approaches one half the surface area of the bounding box.. ie 256 * 256 * 256 voxels requires just 256 + 256 +256 polygons…
Now i can confirm your assumption is completely incorrect regarding overdraw. The view-port represents only a few megabytes of data (any card is capable of hundreds of gigabytes of internal transfer) so as long as your shader is cheap ( ie 1 texture access ) you can overdraw MANY [>64] times without consequence ( tested) …
Finally, any poorly introduced alpha would in this case require texel level rejection or late pass z writing to maintain proper depth occlusion – severely degrading performance because of it’s effect on the hardware early / Hierarchical z implementation but here the answer is again simple – draw each of the 3 groups of dimensional slices into it’s own separate buffer and combine them yourself.
I’ve tried it on a 4096x4096x4096 grid it produced 250,000 polys and the performance was incredible. ( by contrast just greedy meshing produces so many triangles the program could not achieve 1/10 fps )
I’m late to the party, but I wanted to mention a possible problem with the greedy algorithm: cracking. See https://s26.postimg.org/f0zc5l3mh/tverts.png – at the locations marked (and many others) it forms t-vertices. If not corrected, by adding the vertices from one quad to its neighbors, you can get problems with some rendering algorithms. See https://en.wikipedia.org/wiki/T-vertices (which could really be longer). I’m actually surprised I don’t see any t-vertex problems zooming in using your demo – maybe GPUs’ precision really is improving. Or maybe having everything aligned on a grid helps. Have you noticed any cracking?
Can’t you simply explain how to get greedy mesh starting from the culled method ? I mean initially we have a bunch of identical quads. How do you merge them ?
Your explanation is all focused on total ordering of quads. What for ? Can’t you explain the relation between the algorithm, total ordering thing ? You give us no clue about the algorithm.
And sorry but the sample code is literally incomprehensible & ugly.
Its a bit mathy, but the answers are all there.. I’ll attempt to translate into more human vernacular…
For any list of quads; there exists a way to order them such that tall ones come first, within that sub list we could say that wide ones come first, within that left ones come first etc…
What that really means is if you scanned across your voxel field from the top right looking for switched on voxels and then making the tallest quad from that point down and then extending that to the widest quad it can be, you would be effectively generating the quad list he defines as his total order.
Its basically a magical math way to say; we use a really dumb algorithm which is akin to just scanning over in particular order and making ‘pretty good’ quads based on the simple rule of extending in a particular direction. ( he uses sorting of the quad list to get the same results, but that is crazy wasteful and a terrible idea compared to just scanning )
I have implemented the interior culling and the greedy mesh algorithm in a project made with Unity.
For those who’d like to have the code, you can find it here:
https://github.com/ArnaudValensi/warfest-voxel-unity
The greedy mesh is implemented in this file:
https://github.com/ArnaudValensi/warfest-voxel-unity/blob/master/Assets/Core/Scripts/Voxel/ChunkSimplifier.cs
I’ve tried to implement something like this that reads Minecraft levels and generates polygons for lighting, shadows, collision, etc. This technique works well for creating a smaller set of cubes for collision detection. However, I was never able to get rendering to work with the standard Minecraft texture atlas. The problem is there’s no way to assign texture coordinates to the resulting merged quads that properly tile the individual material textures. You would have to split all of the tiny 18×18 textures out of the atlas into their own textures to get UV tiling to work. On top of that, these textures aren’t even a multiple of 4 pixels as required in OpenGL. I wonder how Minecraft handles this?
We’ve used a similar algorithm for splitting 2D Manhattan polygons into rectangles at work. I’ve definitely seen cases where more than E/2 rectangles are required to cover the polygon. However, we use a different total order than you do, so maybe that makes a difference. It’s possible that yours works better, though ours doesn’t require sorting the geometry.
I might be a bit late to the party, but I have an idea for a structure that would maintain dynamic greedy meshes somewhat efficiently.
Firstly, put all possible vertices of a chunk in a single vertex buffer. The offset of each is determined by their position in the chunk. Use this buffer for every chunk you draw.
Now, for every possible face of the chunk (of which there are 2*(n+n+n)=2*3*n since you can slice each chunk along three major planes – each facing two possible ways) create a separate index buffer. You store indices to the vertices of the triangles that are the result of the greedy meshing algorithm for that plane.
This solves the problem of duplicating vertices and separates (somewhat) independent meshes.
There are several things to consider:
1. On each block change, you only have to re-mesh six of those faces (one for every chunk face that that block is a part of).
2. You know which way each of the faces if facing, so you can cull half of them.
3. This method might create triangles that are partially or completely invisible since they might be facing other opaque blocks. This might not necessarily be a bad thing, at least when it comes to partially invisible triangles since it generally creates fewer larger triangles (I think, I never checked). In the case of the completely invisible triangles, those might better be removed but would require extra work to check if they’re invisible. One way to deal with it is to add a mask to every block denoting which face is visible and then removing the triangles all made out of blocks with invisible faces. The benefit of that might depend on the density of the blocks in the chunk.
4. The buffer for each of the greedy meshes is not of the constant size and presents a pretty standard problem of memory fragmentation that I suspect could be solved more elegantly using Vulkan than OpenGL.
This could be used for both raster and ray trace pipelines.
Really like this article! Well written and I’ve used the greedy meshing in 2 different hobby projects so far, and am really happy with the results! Just wanted to say thanks to you for providing all these incredible resources!
I am going to boomark this for now, seriously interested in minecraft and programming!