This is a post about a silly (and mostly pointless) optimization. To motivate this, consider the following problem which you see all the time in mesh processing:
Given a collection of triangles represented as ordered tuples of indices, find all topological duplicates.
By a topological duplicate, we mean that the two faces have the same vertices. Now you aren’t allowed to mutate the faces themselves (since orientation matters), but changing their order in the array is ok. We could also consider a related problem for edges in a graph, or for tetrahedra in mesh.
There are of course many easy ways to solve this, but in the end it basically boils down to finding some function or other for comparing faces up to permutation, and then using either sorting or hashing to check for duplicates. It is that comparison step that I want to talk about today, or in other words:
How do we check if two faces are the same?
In fact, what I really want to talk about is the following more general question where we let the lengths of our faces become arbitrarily large:
Given a pair of arrays, A and B, find a total order 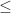
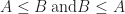

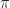
For example, we should require that:
[0, 1, 2]
[2, 0, 1]
And for two sequences which are not equal, like [0,1,2] and [3, 4, 5] we want the ordering to be invariant under permutation.
Obvious Solution
An obvious solution to this problem is to sort the arrays element-wise and return the result:
function compareSimple(a, b) {
if(a.length !== b.length) {
return a.length - b.length;
}
var as = a.slice(0)
, bs = b.slice(0);
as.sort();
bs.sort();
for(var i=0; i<a.length; ++i) {
var d = as[i] - bs[i];
if(d) {
return d;
}
}
return 0;
}
This follows the standard C/JavaScript convention for comparison operators, where it returns -1 if a comes before b, +1 if a comes after b and 0 if they are equal. For large enough sequences, this isn’t a bad solution. It takes 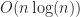
An obvious way to fix this would be to try inlining the sorting function for small values of n (which is all we really care about), but doing this yourself is pure punishment. Here is an `optimized` version for length 2 sets:
function compare2Brutal(a, b) {
if(a[0] < a[1]) {
if(b[0] < b[1]) {
if(a[0] === b[0]) {
return a[1] - b[1];
}
return a[0] - b[0];
} else {
if(a[0] === b[1]) {
return a[1] - b[0];
}
return a[0] - b[1];
}
} else {
if(b[0] < b[1]) {
if(a[1] === b[0]) {
return a[0] - b[1];
}
return a[1] - b[0];
} else {
if(a[1] === b[1]) {
return a[0] - b[0];
}
return a[1] - b[1];
}
}
}
If you have any aesthetic sensibility at all, then that code probably makes you want to vomit. And that’s just for length two arrays! You really don’t want to see what the version for length 3 arrays looks like. But it is faster by a wide margin. I ran a benchmark to try comparing how fast these two approaches were at sorting an array of 1000 randomly generated tuples, and here are the results:
- compareSimple: 5864 µs
- compareBrutal: 404 µs
That is a pretty good speed up, but it would be nice if there was a prettier way to do this.
Symmetry
The starting point for our next approach is the following screwy idea: what if we could find a hash function for each face that was invariant under permutations? Or even better, if the function was injective up to permutations, then we could just use the `symmetrized hash` compare two sets. At first this may seem like a tall order, but if you know a little algebra then there is an obvious way to do this; namely you can use the (elementary) symmetric polynomials. Here is how they are defined:
Given a collection of 


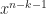

For example, if 
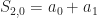

And for 
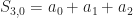

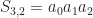
The neat thing about these functions is that they contain enough data to uniquely determine 
function compare2Sym(a, b) {
var d = a[0] + a[1] - b[0] - b[1];
if(d) {
return d;
}
return a[0] * a[1] - b[0] * b[1];
}
Not only is this way shorter than the brutal method, but it also turns out to be a little bit faster. On the same test, I got:
- compare2Sym: 336 µs
Which is about a 25% improvement over brute force inlining. The same idea extends to higher n, for example here is the result for 
function compare3Sym(a, b) {
var d = a[0] + a[1] + a[2] - b[0] - b[1] - b[2];
if(d) {
return d;
}
d = a[0] * a[1] + a[0] * a[2] + a[1] * a[2] - b[0] * b[1] - b[0] * b[2] - b[1] * b[2];
if(d) {
return d;
}
return a[0] * a[1] * a[2] - b[0] * b[1] * b[2];
}
Running the sort-1000-items test against the simple method gives the following results:
- compareSimple: 7637 µs
- compare3Sym: 352 µs
Computing Symmetric Polynomials
This is all well and good, and it avoids making a copy of the arrays like we used in the basic sorting method. However, it is also not very efficient. If one were to compute the coefficients of a symmetric polynomial directly using the naive method we just wrote, then you would quickly end up with 


A slightly better way to compute them is to use the polynomial formula and apply the FOIL method. That is, we just expand the symmetric polynomials using multiplication. This dynamic programming algorithm speeds up the time complexity to 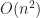
function compare3SymOpt(a,b) {
var l0 = a[0] + a[1]
, m0 = b[0] + b[1]
, d = l0 + a[2] - m0 - b[2];
if(d) {
return d;
}
var l1 = a[0] * a[1]
, m1 = b[0] * b[1];
d = l1 * a[2] - m1 * b[2];
if(d) {
return d;
}
return l0 * a[2] + l1 - m0 * b[2] - m1;
}
For comparison, the first version of compare3 used 11 adds and 10 multiplies, while this new version only uses 9 adds and 6 multiplies, and also has the option to early out more often. This may seem like an improvement, but it turns out that in practice the difference isn’t so great. Based on my experiments, the reordered version ends up taking about the same amount of time overall, more or less:
- compare3SymOpt: 356 µs
Which isn’t very good. Part of the reason for the discrepancy most likely has something to do with the way compare3Sym gets optimized. One possible explanation is that the expressions in compare3Sym might be easier to vectorize than those in compare3SymOpt, though I must admit this is pretty speculative.
But there is also a deeper question of can we do better than
Polynomial multiplication is convolution.
Using a fast convolution algorithm, we can multiply two polynomials together in 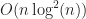
Question: Can we compute the n elementary symmetric polynomials in
Overflow
Now there is still a small problem with using symmetric polynomials for this purpose: namely integer overflow. If you have any indices in your tuple that go over 1000 then you are going to run into this problem once you start multiplying them together. Fortunately, we can fix this problem by just working in a ring large enough to contain all our elements. In languages with unsigned 32-bit integers, the natural choice is 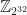
But life is not so simple in the weird world of JavaScript! It turns out for reasons that can charitably be described as “arbitrary” JavaScript does not support a proper integer data type, and so every number type in the language gets promoted to a double when it overflows whether you like it or not (mostly not). The net result: the above approach messes up. One way to fix this is to try applying a modulus operator at each step, but the results are pretty bad. Here are the timings for a modified version of compare2Sym that enforces bounds:
- compare2Masked: 1750 µs
That’s more than a 5-fold increase in running time, all because we added a few innocent bit masks! How frustrating!
Semirings
The weirdness of JavaScript suggests that we need to find a better approach. But in the world of commutative rings, it doesn’t seem like there are any immediately good alternatives. And so we must cast the net wider. One interesting possibility is to extend our approach to include semirings. A semiring is basically a ring where we don’t require addition to be invertible, hence they are sometimes called “rigs” (which is short for a “ring without negatives”, get it? haha).
Just like a ring, a semiring is basically a set 
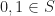
- The complex numbers are semiring (and more generally, so is every field)
- The integers are a semiring (and so is every other ring)
- The natural numbers are a semiring (but not a ring)
- The set of Boolean truth values,
under the operations OR, AND is a semiring (but is definitely not a ring)
- The set of reals under the operations min,max is a semiring (and more generally so is any distributive lattice)
- The tropical semiring, which is the set of reals under (max, +) is a semiring.
In many ways, semirings are more fundamental than rings. After all, we learn to count stuff using the natural numbers long before we learn about integers. But they are also much more diverse, and some of our favorite definitions from ring theory don’t necessarily translate well. For those who are familiar with algebra, probably the most shocking thing is that the concept of an ideal in a ring does not really have a good analogue in the language of semirings, much like how monoids don’t really have any workable generalization of a normal subgroup.
Symmetric Polynomials in Semirings
However, for the modest purposes of this blog post, the most important thing is that we can define polynomials in a semiring (just like we do in a ring) and that we therefore have a good notion of an elementary symmetric polynomial. The way this works is pretty much the same as before:
Let 


And for

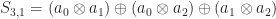

And so on on…
Rank Functions and (min,max)
Let’s look at what happens if we fix a particular semiring, say the (min,max) lattice. This is a semiring over the extended real line 

Now, here is a neat puzzle:
Question: What are the elementary symmetric polynomials in this semiring?
Here is a hint:


And…
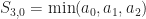
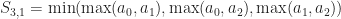
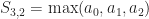
Give up? These are the rank functions!
Theorem: Over the min,max semiring,
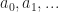
In other words, evaluating the symmetric polynomials over the min/max semiring is the same thing as sorting. It also suggests a more streamlined way to do the brutal inlining of a sort:
function compare2Rank(a, b) {
var d = Math.min(a[0],a[1]) - Math.min(b[0],b[1]);
if(d) {
return d;
}
return Math.max(a[0],a[1]) - Math.max(b[0],b[1]);
}
Slick! We went from 25 lines down to just 5. Unfortunately, this approach is a bit less efficient since it does the comparison between a and b twice, a fact which is reflected in the timing measurements:
- compare2Rank: 495 µs
And we can also easily extend this technique to triples as well:
function compare3Rank(a,b) {
var l0 = Math.min(a[0], a[1])
, m0 = Math.min(b[0], b[1])
, d = Math.min(l0, a[2]) - Math.min(m0, b[2]);
if(d) {
return d;
}
var l1 = Math.max(a[0], a[1])
, m1 = Math.max(b[0], b[1]);
d = Math.max(l1, a[2]) - Math.max(m1, b[2]);
if(d) {
return d;
}
return Math.min(Math.max(l0, a[2]), l1) - Math.min(Math.max(m0, b[2]), m1);
}
- compare3Rank: 618.71 microseconds
The Tropical Alternative
Using rank functions to sort the elements turns out to be much simpler than doing a selection sort, and it is way faster than calling the native JS sort on small arrays while avoiding the overflow problems of integer symmetric functions. However, it is still quite a bit slower than the integer approach.
The final method which I will now describe (and the one which I believe to be best suited to the vagaries of JS) is to compute the symmetric functions over the (max,+), or tropical semiring. It is basically a semiring over the half-extended real line, 



There is a cute story for why the tropical semiring has such a colorful name, which is that it was popularized at an algebraic geometry conference in Brazil. Of course people have known about (max,+) for quite some time before that and most of the pioneering research into it was done by the mathematician Victor P. Maslov in the 50s. The (max,+) semiring is actually quite interesting and plays an important role in the algebra of distance transforms, numerical optimization and the transition from quantum systems to classical systems.
This is because the (max,+) semiring works in many ways like the large scale limit of the complex numbers under addition and multiplication. For example, we all know that:
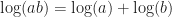
But did you also know that:

This basically a formalization of that time honored engineering philosophy that once your numbers get big enough, you can start to think about them on a log scale. If you do this systematically, then you eventually will end up doing arithmetic in the (max,+)-semiring. Masolv asserts that this is essentially what happens in quantum mechanics when we go from small isolated systems to very big things. A brief overview of this philosophy that has been translated to English can be found here:
Litvinov, G. “The Maslov dequantization, idempotent and tropical mathematics: a very brief introduction” (2006) arXiv:math/0501038
The more detailed explanations of this are unfortunately all store in thick, inscrutable Russian text books (but you can find an English translation if you look hard enough):
Maslov, V. P.; Fedoriuk, M. V. “Semiclassical approximation in quantum mechanics”
But enough of that digression! Let’s apply (max,+) to the problem at hand of comparing sequences. If we expand the symmetric polynomials in the (max,+) world, here is what we get:

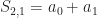
And for
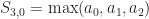
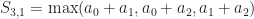

If you stare at this enough, I am sure you can spot the pattern:
Theorem: The elementary symmetric polynomials on the (max,+) semiring are the partial sums of the sorted sequence.
This means that if we want to compute the (max,+) symmetric polynomials, we can do it in
Working the (max,+) solves most of our woes about overflow, since adding numbers is much less likely to go beyond INT_MAX. However, we will tweak just one thing: instead of using max, we’ll flip it around and use min so that the values stay small. Both theoretically and practically, it doesn’t save much but it gives us a maybe a fraction of a bit of extra address space to use for indices. Here is an implementation for pairs:
function compare2MinP(a, b) {
var d = a[0]+a[1]-b[0]-b[1];
if(d) {
return d;
}
return Math.min(a[0],a[1]) - Math.min(b[0],b[1]);
}
And it clocks in at:
- compare2MinP: 354 µs
Which is a bit slower than the symmetric functions, but still way faster than ranking. We can also play the same game for
function compare3MinP(a, b) {
var l1 = a[0]+a[1]
, m1 = b[0]+b[1];
d = l1+a[2] - (m1+b[2]);
if(d) {
return d;
}
var l0 = Math.min(a[0], a[1])
, m0 = Math.min(b[0], b[1])
, d = Math.min(l0, a[2]) - Math.min(m0, b[2]);
if(d) {
return d;
}
return Math.min(l0+a[2], l1) - Math.min(m0+b[2], m1);
}
Which hits:
- compare3MinP: 382 µs
Again, not quite as fast as integers, but pretty good for JavaScript.
Summary
You can get all the code to run these experiments on github:
https://github.com/mikolalysenko/set-compare
And here are the results that I got from running the experiment, all collated for easy reading:
Dimension = 2
- compareSimple: 5982 µs
- compare2Brutal: 415 µs
- compare2Sym: 352 µs
- compare2SymMasked: 1737 µs
- compare2Rank: 498 µs
- compare2MinP: 369 µs
Dimension = 3
- compareSimple: 7737 µs
- compare3Sym: 361 µs
- compare3Sym_opt: 362 µs
- compare3Rank: 612 µs
- compare3MinP: 377 µs
As you can see, the (min,+) solution is nearly as fast as the symmetric version without having the same overflow problems.
I hope you enjoyed reading this as much as I enjoyed tinkering around! Of course I still don’t know of an optimal way to compare two lists. As a final puzzle, I leave you with the following:
Question: Is there any method which can test if two unordered sequences are equal in linear time and at most log space?
Frankly, I don’t know the answer to this question and it may very well be impossible. If you have any thoughts or opinions on this, please leave a comment!

It’s true that [0, 1, 2] == [2, 0, 1], but we can’t say that say that [0, 1, 2] == [0, 2, 1], right?. This makes the problem of finding duplicate polygons a whole lot easier (and faster). I’m assuming you know this and therefor I’m asking:
Why do you want the ordering to be invariant under permutation? For finding duplicate polygons within a mesh you don’t want this condition.
That’s a slightly different problem, but you can still solve it using a similar idea based on alternating polynomials:
http://en.wikipedia.org/wiki/Alternating_polynomial
A simple example of these are the Vandermonde polynomials, which arise from the cofactor expansion of a matrix:
http://en.wikipedia.org/wiki/Vandermonde_polynomial
How these generalize to semirings though is less clear, since it seems like you need to be able to subtract in order to get the `alternating` property to work, but the idea should work in integer arithmetic.
Semirings indeed sound problematic for use with alternating polynomials, but I could imagine using a complemented lattice. I haven’t checked whether this actually “works” (in the sense that it gives useful results), but the Vandermonde polynomial for n=2 would be something like min(x_1,x_2^C) (which is indeed “alternating” if one replaces negation by complementation). However, I don’t think the trick with “multiplying” with a symmetric polynomial works here, so a generalization would not be immediate.
Okay, firstly I don’t understand this post. Secondly, it’s pretty cool. Thirdly, I have a curious thought. A bad (because it wastes memory) but interesting alternative to sorting an array is to not sort the array but return a new array which carries the information of how the array should be sorted. For example, the array [‘a’, ‘c’, ‘b’] would result in the array [0, 2, 1]. So the comparison function would also have the bad alternative of a function which takes two arrays to compare, and two arrays showing how those arrays are sorted. I’m curious, and wonder is there a similar bad alternative for the comparison function which does not sort the lists?
Actually, the language J does that exact thing in sorting lists. The function “/:” when it is monadic, or takes a single argument, returns the sequence that shows the order of the elements. The dyadic “/:” is defined to be “(/: y ) { x “, where “{” is “nth”, “x” is the left argument and “y” is the left.
/: ‘edfbac’
4 3 5 1 0 2
/:~ ‘edfbac’
abcdef
“~” is a function modifier which takes the left argument and makes it both the left and right argument for the function.
http://www.jsoftware.com/help/dictionary/d422.htm
Quick implementation note – consider adding | 0 to make addition and subtraction (but not multiplication) faster, since JS engines can recognize that the result is being casted to an int32 and remove overflow checks.
(max,+) isn’t really a tropical semiring. It’s the dual of a tropical semiring; namely, it’s the log-domain Viterbi semiring. The actual tropical semiring is (min,+) whereas the standard Viterbi semiring is (max,*). I discuss these and other alternatives over here.
I just started reading the Symmetry section, but if I understand this correctly, it seems that you have S(2,0) and S(2,1) reversed.
If n = 2, you get (x+a0)(x+a1) = S(2,0) + S(2,1)x + x^2
the first part becomes a0*a1 + (a0 + a1)x + x^2
so it looks to me like S(2,0) = a0*a1 and S(2,1) = (a0 + a1)
so I think you want to switch that in your post.
Thanks! I apologize for the nasty formatting, and I hope I understand the rest of your post. 🙂
Good catch! I changed the definition so that it should now be consistent.
Nice Read. How about this: make a list with a large enough number of primes, say primeList. Then a and b are equal iff primeList[a[0]] * primeList[a[1] * primeList[a[2]] == primeList[b[0]] * primeList[b[1] * primeList[b[2]]
Quite interested in the benchmark results 🙂
My mind, she is blown. It’s so rare (but so cool!) to see abstract algebra applied usefully to a real-world problem, outside of specialized domains like crypto.
Nice blog!
Two unordered sequences A=(a1, .., an) and B=(b1,…,bn) are equal
iff the polynomial f(x)=(x-a1)(x-a2)…(x-an) and g(x) = (x-b1)..(x-bn) are equal.
iff f(x) and g(x) have the same coefficients w.r.t some basis (of vector space of polynomials)
The approaches explore different choice for +,* and different choice of basis.
For the question: Is there any method which can test if two unordered sequences are equal in linear time and at most log space?
f(x) = g(x) are equal as polynomials iff f(k)=g(k) for all k=1..n
If you don’t mind probabilistic algorithms, check if f(k) = g(k) for a random k in (1,..,n).
In practice if you expect f and g to be different, you can try a few values of k, and if they cannot distinguish between f and g, do the O(n log n) approach. I won’t be surprised if this has expected linear running time.
Sorry not really understand what you doing 😉
function compare2Sym(a, b) {
var d = a[0] + a[1] – b[0] – b[1];
if(d) {
return d;
}
return a[0] * a[1] – b[0] * b[1];
}
a{1,3} b{0,4}
d = 0;
a == b ??
here I create really strange way to filter unique vertex from 2 array, I think it fast =)
fast for big arrays where vertex X limited -5000 to 5000 float val
Arraylist temp [10 001] // 10k vertex from -5k to +5k
vertex = array[3] //x y z //can add array pos if also need copy to uniq tex Cord or light info//
float a[] //x y z
float b[] // x y z
for(int i = 0; i < a.size; i += 3){
float x = a[i];
float y = a[i + 1];
float z = a[i + 2];
temp[(int)x].add({x, y, z});
}
float unic[Max(a.size, b.size)];
int unic_next = 0;
for(int i = 0; i < b.size; i += 3){
float x = bi];
float y = b[i + 1];
float z = b[i + 2];
Arraylist list = temp[(int)x];
if(list.size == 0){//or list == null
unic[unic_next++] = x;
unic[unic_next++] = y;
unic[unic_next++] = z;
// dont have same add to unic
/*
//add to uniq
int pos = i / 3;
b_Tex[pos]
b_Tex[pos + 1]
b_Light[i]
b_Light[i + 1]
b_Light[i + 2]
*/
}
else{
boolean find;
for(int j = 0; j < list.size; j++){
vertex ver = list[j];
if(ver[0] == x && ver[1] == y && ver[2] == z){
find = true;
break;
}
}
if(!find){
unic[unic_next++] = x;
unic[unic_next++] = y;
unic[unic_next++] = z;
// dont have same add to unic
/*
//add to uniq
int pos = i / 3;
b_Tex[pos]
b_Tex[pos + 1]
b_Light[i]
b_Light[i + 1]
b_Light[i + 2]
*/
}
}
}
//we add uniq vertex from B array now add from A
for(int i = 0; i < temp.size; i++){
Arraylist list = temp[i];
for(int j = 0; j < list.size; j++){
vertex ver = list[j];
unic[unic_next++] = ver[0];
unic[unic_next++] = ver[1];
unic[unic_next++] = ver[2];
/*
//add to uniq
int pos = ver[3] / 3; //array pos
a_Tex[pos]
a_Tex[pos + 1]
a_Light[i]
a_Light[i + 1]
a_Light[i + 2]
*/
}
}
//delete temp =)
Omg sorry all code indentation disappear.
Ups my mistake you compare triangles not vertex, not big problem(modyfi my code) if they have same sequins like [0,1,2] [0,1,2]
But if not [0,1,2][2,1,0]
add [0,1,2] to global array[0], [1], and array[2] with boolean clone = true on all after first then when add unic simple check Boolean; ^^
Also if you want optimase add uniq from 10000 array
You may create Arraylist that hold only pos_id witch have triangles
{
If(temp[(int)x].. size == 0){
Used_Temp.add((int)x)
}
temp[(int)x].add({x, y, z});
}
{
//for(int i = 0; i < temp.size; i++)
for(int i = 0; i < Used_Temp.size; i++)
Arraylist list = temp[Used_Temp[i]];
}
Hire is my final solution ^^ in text for easiest understanding
Create temp array[][] wher fist size = a.size
And second with max number triangles per same vertex
[0,1,2][0,1,3] array size 2
Add all triangles from “a” to temp where temp[pos][pos2]
pos = min vertex from triangle
pos2 = iterator++
now for all in array “b”
pos = get min vertex from triangle
compare with temp[pos][x] if don’t find triangle add to unic
now need only add all triangles from ”a”
– because “b” we already filtered
=)
Thanks moderator for publish my answer, this working java demo 😉
source code
http://www.2shared.com/file/5FmLvC6e/Triangl_Compare.html
(lower download button ^^)
(moder plz delete previous post, hi have some IDE info that prevent simple compile, forget about that 😉 )
Thanks moderator for publish my answer, this working java demo 😉
source code
http://www.2shared.com/complete/eXoV588n/Triangl_Compare.html
(lower download button ^^)
Fun post! Really makes me want to read more about the (max,+)-semiring.
This was a good idea: “The starting point for our next approach is the following screwy idea: what if we could find a hash function for each face that was invariant under permutations? Or even better, if the function was injective up to permutations […]”
We can build a hash like that out of ordinary hash functions in a familiar way: for each element in the original array, insert it as a key into a hash table with initial value 1, and increment the value each time that same element appears in the array. (It’s possible to build a hash table so that its natural order is invariant to permutions of insertion order, just by generating more hash bits to resolve collisions.) So if we had [2, 0, 2], we’d create the hash table {2: 2, 0: 1}.
Interpret a serialization of the hash table as a big int, and you’ve got a permutation-invariant hash (actually an injective function up to permutations) in I think amortized linear time.
Comparing two arrays this way does consume linear space worst-case, so it’s not quite an answer to your question, but maybe there’s some way to optimize from here. (Though my money is on linear time log space being impossible.)
Implementing this efficiently in js is maybe kind of a pain. Objects iterate in insertion order and even if you can get access to hash order somehow, the underlying hash table might not be invariant to insertion order. I think you’d need to write a careful hash table implementation in js.
It might be interesting to compare how Blas/Lapack actually have been translated to Java, and how the performance of such has or has not improved as the Java stack has improved.
Darn. This comment was supposed to be on the next article “Implementing Multidimensional Arrays in JavaScript.”
I know this is years after the fact, but I found this article interesting. If I’m not mistaken, don’t strings of bits form a ring (if not a field) under bitwise-and, bitwise-xor? With this ring, there’d be no chance of overflow, and you could support non-arithmetic types. Though it still doesn’t solve the JavaScript problem.
The problem with bitwise AND/XOR is that while it does form a ring, it doesn’t form a unique factorization domain. As a result the symmetric functions don’t produce unique sequences.