It has been a while since I’ve written a post, mostly because I had to work on my thesis proposal for the last few months. Now that is done and I have a bit of breathing room I can write about one of the problems that has been bouncing around in my head for awhile, which is how to implement browser based networked multiplayer games.
I want to write about this subject because it seems very reasonable that JavaScript based multiplayer browser games will become a very big deal in the near future. Now that most browsers support WebWorkers, WebGL and WebAudio, it is possible to build efficient games in JavaScript with graphical performance comparable to native applications. And with of WebSockets and WebRTC it is possible to get fast realtime networked communication between multiple users. And finally with node.js, it is possible to run a persistent distributed server for your game while keeping everything in the same programming language.
Still, despite the fact that all of the big pieces of infrastructure are finally in place, there aren’t yet a lot of success stories in the multiplayer HTML 5 space. Part of the problem is that having all the raw pieces isn’t quite enough by itself, and there is still a lot of low level engineering work necessary to make them all fit together easily. But even more broadly, networked games are very difficult to implement and there are not many popular articles or tools to help with this process of creating them. My goal in writing this series of posts is to help correct this situation. Eventually, I will go into more detail relating to client-server game replication but first I want to try to define the scope of the problem and survey some general approaches.
Overview of networked games
Creating a networked multiplayer game is a much harder task than writing a single player or a hot-seat multiplayer game. In essence, multiplayer networked games are distributed systems, and almost everything about distributed computing is more difficult and painful than working in a single computer (though maybe it doesn’t have to be). Deployment, administration, debugging, and testing are all substantially complicated when done across a network, making the basic workflow more complex and laborious. There are also conceptually new sorts of problems which are unique to distributed systems, like security and replication, which one never encounters in the single computer world.
Communication
One thing which I deliberately want to avoid discussing in this post is the choice of networking library. It seems that many posts on game networking become mired in details like hole punching, choosing between TCP vs UDP, etc. On the one hand these issues are crucially important, in the same way that the programming language you choose affects your productivity and the performance of your code. But on the other hand, the nature of these abstractions is that they only shift the constants involved without changing the underlying problem. For example, selecting UDP over TCP at best gives a constant factor improvement in latency (assuming constant network parameters). In a similar vein, the C programming language gives better realtime performance than a garbage collected language at the expense of forcing the programmer to explicitly free all used memory. However whether one chooses to work in C or Java or use UDP instead of TCP, the problems that need to be solved are essentially the same. So to avoid getting bogged down we won’t worry about the particulars of the communication layer, leaving that choice up to the reader. Instead, we will model the performance of our communication channels abstractly in terms of bandwidth, latency and the network topology of the collective system.
Administration and security
Similarly, I am not going to spend much time in this series talking about security. Unlike the choice of communication library though, security is much less easily written off. So I will say a few words about it before moving on. In the context of games, the main security concern is to prevent cheating. At a high level, there are three ways players cheat in a networked game:
- Exploits: Which use bugs in the game logic to directly manipulate the state for the player’s advantage. (eg. Flight, Duping, etc.)
- Information leakage: Which snoops on parts of the state that should not be visible to the player. (eg. MapHacking, WallHacking, etc.)
- Automation: Which uses scripts/helper programs to enhance player performance and repeat trivial tasks. (eg. AimBot, Macros, etc.)
Preventing exploits is generally as “simple” as not writing any bugs. Beyond generally applying good software development practices, there is really no way to completely rule them out. While exploits tend to be fairly rare, they can have devastating consequences in persistent online games. So it is often critical to support good development practices with monitoring systems allowing human administrators to identify and stop exploits before they can cause major damage.
Information leakage on the other hand is a more difficult problem to solve. The impact of information leakage largely depends on the nature of the game and the type of data which is being leaked. In many cases, exposing positions of occluded objects may not matter a whole lot. On the other hand, in a real time strategy game revealing the positions and types of hidden units could jeopardize the fairness of the game. In general, the main strategy for dealing with information leakage is to minimize the amount of state which is replicated to each client. This is nice as a goal, since it has the added benefit of improving performance (as we shall discuss later), but it may not always be practical.
Finally, preventing automation is the hardest security problem of all. For totally automated systems, one can use techniques like CAPTCHAs or human administration to try to discover which players are actually robots. However players which use partial automation/augmentation (like aimbots) remain extremely difficult to detect. In this situation, the only real technological option is to force users to install anti-cheating measures like DRM/spyware and audit the state of their computer for cheat programs. Unfortunately, these measures are highly intrusive and unpopular amongst users, and because they ultimately must be run on the user’s machine they are vulnerable to tampering and thus have dubious effectiveness.
Replication
Now that we’ve established a boundary by defining what this series is not about it, we can move on to saying what it is actually about: namely replication. The goal of replication is to ensure that all of the players in the game have a consistent model of the game state. Replication is the absolute minimum problem which all networked games have to solve in order to be functional, and all other problems in networked games ultimately follow from it.
The problem of replication was first studied in the distributed computing literature as a means to increase the fault tolerance of a system and improve its performance. In this sense video games are a rather atypical distributed system wherein replication is a necessary end unto itself rather than being just a means unto an end. Because it has priority and because the terminology in the video game literature is wildly inconsistent, I will try to follow the naming conventions from distributed computing when possible. Where there are multiple or alternate names for some concept I will do my best to try and point them out, but I can not guarantee that I have found all the different vocabulary for these concepts.
Solutions to the replication problem are usually classified into two basic categories, and when applied to video games can be interpreted as follows:
- Active replication: Inputs from the players are sent to all players in the network, state is simulated deterministically and independently on each client (also called lock-step synchronization and state-machine synchronization)
- Passive replication: Inputs from the players (clients) are sent to a single machine (the server) and state updates are broadcast to all players. (also called primary backup, master-slave replication, and client-server).
There are also a few intermediate types of replication like semi-active and semi-passive replication, though we won’t discuss them until later.
Active replication
Active replication is probably the easiest to understand and most obvious method for replication. Leslie Lamport appears to have been the first to have explicitly written about this approach and gave a detailed analysis (from the perspective of fault tolerance) in 1978:
Lamport, L. (1978) “Time, clocks and the ordering of events in distributed systems” Communications of the ACM
That paper, like many of Lamport’s writings is considered a classic in computer science and is worth reading carefully. The concept presented in the document is more general, and considers arbitrary events which are communicated across a network. While in principle there is nothing stopping video games from adopting this more general approach, in practice active replication is usually implemented by just broadcasting player inputs.
It is fair to say that active replication is kind of an obvious idea, and was widely implemented in many of the earliest networked simulations. Many classic video games like Doom, Starcraft and Duke Nukem 3D relied on active replication. One of the best writings on the topic from the video game perspective is M. Terrano and P. Bettner’s teardown of Age of Empire’s networking model:
M. Terrano, P. Bettner. (2001) “1,500 archers on a 28.8” Gamasutra
While active replication is clearly a workable solution, it isn’t easy to get right. One of the main drawbacks of active replication is that it is very fragile. This means that all players must be initialized with an identical copy of the state and maintain a complete representation of it at all times (which causes massive information leakage). State updates and events in an actively synchronized system must be perfectly deterministic and implemented identically on all clients. Even the smallest differences in state updates are amplified resulting in catastrophic desynchronization bugs which render the system unplayable.
Desynchronization bugs are often very subtle. For example, different architectures and compilers may use different floating point rounding strategies resulting in divergent calculations for position updates. Other common problems include incorrectly initialized data and differences in algorithms like random number generation. Recovering from desynchronization is difficult. A common strategy is to simply end the game if the players desynchronize. Another solution would be to employ some distributed consensus algorithm, like PAXOS or RAFT, though this could increase the overall latency.
Passive replication
Unlike active replication which tries to maintain concurrent simulations on all machines in the network, in passive replication there is a single machine (the server) which is responsible for the entire state. Players send their inputs directly to the server, which processes them and sends out updates to all of the connected players.
The main advantage of using passive replication is that it is robust to desynchronization and that it is also possible to implement stronger anti-cheating measures. The cost though is that an enormous burden is placed upon the server. In a naive implementation, this server could be a single point of failure which jeopardizes the stability of the system.
One way to improve the scalability of the server is to replace it with a cluster, as is described in the following paper:
Funkhouser, T. (1995) “RING: A client-server system for multi-user virtual environments” Computer Graphics
Today, it is fair to say that the client-server model has come to dominate in online gaming at all scales, including competitive real-time strategy games like Starcraft 2, fast paced first person shooters like Unreal Tournament and even massively multiplayer games like World of Warcraft.
Comparisons
To compare the performance of active versus passive replication, we now analyze their performance on various network topologies. Let 
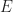

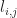
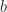

In the case of active replication, the latency is proportional to the diameter of the network. This is minimized in the case where the graph is a complete graph (peer-to-peer) giving total latency of 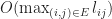
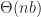
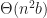
To analyze the performance of passive replication, let us designate player 0 as the server. Then the latency of the network is at most twice the round trip time from the slowest player to the server. This is latency is minimized by a star topology with the server at the hub, giving a latency of 
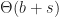

Conclusion
Since each player must be represented in the state, we can conclude that 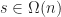
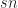
In the next few articles, we will discuss client-server replication for games in more detail and explain how some of these bandwidth and latency optimizations work.

Although some of the subjects you skipped over lightly (NAT Traversal, etc) are still not entirely a solved problem in practice (depending on chosen framework/language) I agree that there are a huge quantity of articles already out there and it was a nice change to see you focus on the core of the subject. The analytical approach is a breath of fresh air too.
The only note of contention I have with your conclusion is that you ignore what the design of the game requires – Some developers may not have the resources or business case to develop a client-server architecture (both remote or local). Or maybe the design of the game allows for a more loosely synchronized state machine (Turn-based games).
I look forward to your upcoming articles – Something I’ve been personally looking into is how games like Battlefield 4 work so well under latency. I suspect its a typical client-server event system with a very well done layer of local prediction and user feedback.
Some thoughts on the subject.
For active replication it is enough to only send inputs from every player to every other player. Every player will send and receive N * size_of_input data. Regardless of world complexity.
For passive replication every player will only send size_of_input_data, but the server has to send out N * size_of_world_delta_update. Which is MUCH bigger. Since latency is at least partially affected by the size of data to be sent, passive replication is much less efficient for a big game world. But of course other advantages can’t be denied.
In the real world Passive Replication is very workable if you apply some basic intelligence such as only sending updates to players if they can see the objects that need updating. Its usually very cheap to do, depending on the genre of game – Open world Vs. closed-corridor FPS.
To expand on strichmond’s reply, a server running a large game world will almost never send N responses for a given request, especially in the case of an MMO.
Say you have 3,000 people on a server, and a group of 20 players are fighting an outdoor boss. One of the players casts an area-of-effect healing spell that hits all 20 players. Say some of them have talents which share healing with people around them in addition to other secondary effects, potentially leading to hundreds of discrete updates which must be applied to 20 entities and then sent to those 20 players and anybody nearby.
This is a relatively expensive event in MMO terms, but it is completely unknown to the majority of the people playing the game, and the server doesn’t have to send this event to anybody out of range of that combat. Instead, when players enter that area, they’ll simply be given up-to-date snapshots of the other players there (which are then updated as described above). If the boss was killed, it simply won’t be around to send information about at all to new players walking through that area until it respawns.
The same is true for NPC AI. Some things can actually be done the active/simulation way, like say a patrolling guard whose position is given as a function of time and a path just needs a moderately accurate clock update to work correctly (it won’t be to a player’s advantage to modify this information since the server will just ignore requests against a target if the positions don’t work out, and the player won’t see the monsters if they’re in aggro range and the server is about to have them attack, etc). But if the monsters required active pathfinding, simple spatial partitioning and cell population tests allow the server to suspend updates unless there is anybody around to receive them, and then only send those updates to players in range.
For many reasons (security being one but others are just as important), this is easier (and possibly more efficient) to handle with sparse passive replication, and the size/bandwidth requirements of even very complex updates are quite manageable in practice.
It’s also helpful in practice to have such a system when it comes to resolving high player density in a given area. If you play WoW, you see this in the first new zone for high level players in every expansion. The size of the logical world that is visible to your player shrinks, and the tolerated latency before considering somebody disconnected increases, as the server adapts to handle congestion in these very dense areas. This lowers the number of event side-effects that the server has to worry about, something which would be extremely difficult to manage in an active replication environment with no simple way to scale that number down without immediately desynchronizing hundreds of players or introducing so much latency players only make one request per second or something along those lines.
There is also no need for the AI clock to vary as described in the Age of Empires article (which was very interesting!). which is good, because that’s a global (or at least per-thread) thing which shouldn’t adapt to one high-congestion area and the leave the rest of the game nearly unplayable as a result.
And that ignores another issue of active replication, which would be asking a client’s computer to run the game logic for pretty much the entire MMO while also rendering their part of it. Yikes!
I was mostly concerned about multiplayer shooters or other games that use smaller worlds, but still need to support a decent amount of players that can potentially meet each other within, say 10 seconds. In this case, sparse replication won’t save much at all. Running game logic is also a non-issue mostly, typical server is not much faster than typical client PC, 2-5 times at most, if client HW is really slow. And the cost of simulating the world in many such games actually doesn’t add much to the cost of rendering the stuff on screen. Main problem of this approach is consistency and security which should be resolved by using more careful programming of simulation logic and using server-side verification.
Or to sum this up, I assumed maps with decent detail but with limited amount of players, something a single server _or_ a single client can handle with relative ease. Even if server still has to run the simulation for obvious reasons, bandwidth savings will be huge, latency smaller.