Last time, I wrote about how to generate meshes in a Minecraft-style voxel engine. I got a lot of interesting feedback, and so today I’m going to do a follow up highlighting some of the points that came up in the various discussions. I’ll also talk about yet another interesting approach to generating meshes, which occurred to me in the mean time. But first, I would like to take a moment to address some specific comments relating to greedy meshing:
Multiple Voxel Types
By far, the most frequent question about greedy meshing was how to extend it to handle multiple voxel types and different normal directions. This surprised me somewhat, though it is perhaps understandable since I did not spend much time explaining it in the previous post. The general idea is pretty simple. What you do is group blocks together according to their type, and then do the meshing on each part separately:

That’s it! This same idea works for normals too. All you need to do is add an extra bit to keep track of the orientation. To show that this isn’t so difficult, I made an updated demo that shows how some of these methods work for different voxel types.
T-Junctions
Now this one is pretty bizarre. By far the most common criticism of the greedy method I saw on reddit was that the meshes contain many T-vertices. I’m not really sure why so many people latched on to this concept, but it is certainly true that greedy meshing will produce them. What is less clear though is what the harm of having a T-junction is.
Intuitively, one would assume that as long as you have a pair of colinear edges, subdividing one of them shouldn’t make much difference (at least that’s what one would hope anyway). After thinking fairly hard about rendering, I couldn’t come up with a good reason why this would be a problem, and so I decided to code up a demo to test it:
Click here to see the T-Junction Demo!
Surprisingly, no matter how I messed with the parameters I couldn’t get any visible discontinuity to show up! Here are some pictures:

The mesh with edges drawn on to show the T-junctions.

The mesh without edges drawn on.
In summary, I’m not sure that there is actually a problem with T-junctions. You can try out the demo yourself if you aren’t convinced. If anyone can come up with a plausible scenario where one of the greedy meshes has visible rendering artefacts, I’d be quite interested to see it. I’ve heard old ghost stories that on some ancient ATi cards, when the moon is full, these type of cracks actually do appear and make a big difference; but I unfortunately do not have access to such hardware. If you can manage to get a crack to show up in this demo (using WebGL), please take a screen shot and post a comment.
From Quads to Triangles
That much concludes what I have to say about greedy meshing. The next thing I want to discuss is an efficient alternative to greedy meshing. The inspiration for this idea comes from a comment made by fr0stbyte on the last post. Implicitly, he asked the question of whether triangles could be used to create better meshes than quads. Thinking about this made me realize that there is a much more direct way to optimize Minecraft-type meshes using standard computational geometry techniques. Ultimately, we can just think of this problem as just plain-old ordinary polygon triangulation, and solve it using purely classical methods. Starting from scratch, it is by no means a trivial thing to figure out how to triangulate a polygon, however it is by now very well understood and something of a standard technique (which makes me feel very foolish for having overlooked such a basic connection earlier 😐 ).
One of the most frequently used methods for polygon triangulation is the monotone decomposition algorithm due to Fournier et al. The basic algorithm proceeds in two steps:
- Decompose your polygon into monotone polygons.
- Triangulate each monotone polygon.
The second step can be done in optimal linear time on the number of vertices of the monotone polygon, and is quite well documented elsewhere. I won’t spend any time discussing it here, and instead I’ll just point you to a standard tutorial or text book. The more interesting problem in this context is how to do the first step efficiently. It can be shown that for non-simple polygons (of which our regions generally are), it requires at least 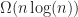

However, in the case of Minecraft-style meshing, we can actually do much better. The key thing is to realize that the number of voxels is strictly much greater than the number of vertices. This suggests that we can cover the cost of generating the monotone subdivision by the fixed cost of walking along the voxels, and still get an 
- Initialize polygons, frontier to empty list
- For each scan line:
- Run length encode scan line
- Set pf = pointer to start of frontier, pr = pointer to start of runs
- While pf and pr are not at the end of their respective lists:
- Let r = *pr and p = *pf be the run and polygon at current positions
- If r overlaps with the bottom of pf and is the same type:
- Merge r with p
- Increment pr and pf and continue
- If the end of r is past the bottom right of p:
- Close off p and remove from frontier
- Increment pf
- If the bottom end of p is past the end of r:
- Turn r into a new monotone polygon
- Increment pr
- Close off all remaining polygons on the frontier
That looks like a terrible mess, but hopefully it makes some sense. If it helps, here is some actual javascript which implements this method. The time complexity of this approach is dominated by the cost of voxel traversal, and so it is
WebGL Demo!
Without further ado, here is the link:
Click here to see the WebGL demo!
The main changes from last time are the addition of different colors and types for voxels, the extension to handle orientations and the addition of a new algorithm. Here are some pictures for comparison:
Left: Naive culling, Middle: Greedy, Right: Monotone



Naive: 26536 verts, 6634 quads. Greedy: 7932 verts, 1983 quads. Monotone: 7554 verts, 4306 tris.



Naive: 19080 verts, 4770 quads. Greedy: 8400 verts, 2100 quads. Monotone: 8172 verts, 4572 tris.



Naive: 1344 verts, 336 quads. Greedy: 264 verts, 66 quads. Monotone: 204 verts, 104 tris.
While monotone meshing is at least conceptually straightforward, the mesh quality isn’t noticeably different. One thing to keep in mind is that the primitive counts for the monotone mesh are in triangles, while the other two measurements are given in quads. Thus, there is a factor of two difference between the quantities. In all of the examples, the monotone mesh had the fewest vertices. The reason for this is that the monotone triangle decomposition code pushes all the vertices up front, while the greedy mesher emits a new set of vertices per each quad. It would be interesting to see if the greedy mesh vertex count could be reduced using some similar method. On the other hand, the adjusted primitive count (taking each quad as 2 triangles) swings both ways. On the terrain example, greedy meshing was a little better, while on the triangle example monotone wins by a similar margin.
In the end it is hard to declare a clear winner from this data. Both greedy and monotone meshing have their advantages and draw backs, and there are situations where the primitive count advantage can swing easily from one to the other. One slight edge should be given to the greedy method in terms of code complexity, though only barely. On the other hand, if your rendering is vertex shader limited, you may gain some small FPS boost by switching to monotone meshing since the vertex count is typically lower. This saves a bit of GPU memory, which is always nice, but the savings are so small that I’d have a hard time believing it is that big of a deal.
Overtime Shoot Out
To break the stalemate, let’s race the different meshers against each other. Recall that in terms of performance, the cost of each algorithm can be broken down into two factors:
- The size of the underlying voxel grid,
- The number of surface primitives,
.
One way to think of these two parameters is that 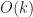

 .
.As 
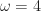
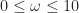
Here is the data from running this benchmark on the naive culling method:
Naive Meshing Results:
0 81.80 0 0
1 129.05 82488 20622
2 147.85 114696 28674
3 166.50 146016 36504
4 180.80 178792 44698
5 206.10 209256 52314
6 208.45 243672 60918
7 258.85 272304 68076
8 267.60 306640 76660
9 278.45 334968 83742
10 297.15 371496 92874
The first column is
Stupid Meshing Results:
0 6.95 0 0 1 2733.65 3293184 823296 2 2848.05 3292128 823032 3 2727.35 3293184 823296 4 2673.40 3289032 822258 5 2729.50 3293184 823296 6 2741.10 3293088 823272 7 2687.75 3293184 823296 8 2729.20 3286512 821628 9 2682.40 3293184 823296 10 2772.95 3293136 823284
This may at first seem a little bizarre, but it makes sense. For stupid meshing, iterating over the volume is basically `free’. The only limit at the end is the memory bandwidth. Another weird thing is that the number of primitives in the stupid mesh does not scale with surface area, but rather with volume. In this case, the volume of each region is relatively constant and so the run-time quickly spikes to 2.7 seconds or so, then stays flat as the frequency changes.
Anyway, let’s now get to the main point, which is how well greedy and monotone meshing stack up:
Greedy Meshing: Monotone Meshing:
0 92.40 0 0 0 79.00 0 0 1 99.10 20712 5178 1 92.20 20202 11034 2 103.10 44068 11017 2 110.10 43326 23631 3 110.35 61644 15411 3 122.30 60420 32778 4 126.00 87984 21996 4 144.60 86328 47319 5 134.25 102024 25506 5 155.80 100056 54033 6 151.40 129344 32336 6 192.10 127074 68871 7 153.60 142416 35604 7 197.40 139476 75273 8 167.85 172140 43035 8 227.60 167410 92843 9 164.90 182256 45564 9 239.60 178302 96081 10 198.30 213452 53363 10 297.60 209838 113559
A victory for greedy meshing! Not only did it beat monotone meshing, but for sufficiently complicated geometry it is also the fastest method overall. Though this is not exactly a fair apples-to-apples comparison, since greedy meshing spits out quads while monotone meshing generates triangles. This fact alone is enough to account for nearly a 30% difference in performance, and explains some, but not all of the discrepancy between these two charts. The remainder of the overhead is most likely due to the fact that Monotone meshing is a more complex algorithm and that it has to do a bit more work per triangle, while greedy meshing is a bit simpler, but does more work per voxel.
While I believe that the general conclusions of these benchmarks are valid, I wouldn’t say that this definitively proves greedy meshing is faster than monotone meshing. Javascript is far from the best language to use for doing benchmarks, and these implementations are not particularly tuned for performance. There may also be subtle bugs lurking in the code somewhere, like silent out of bounds accesses, that could end up having disastrous consequences for performance (and account for nearly the entire gap between the two algorithms). I’ve also tried to control for as many variables as I could, but it is still possible that I overlooked something and that there is some systemic bias in these results.
Conclusion
We’ve now seen at least two different ways to do better than naive meshing in Minecraft, and there are probably many others out there. Portponky from r/gamedev sent me some C++ code to generate meshes, though I’ve not yet looked at it carefully enough to figure out how to port it to Javascript (sorry!). I am still quite curious about it though, since it seems to be doing something quite different than either the greedy method or monotone triangulation. Anyway, that’s all for now. If you have any questions or other interesting thoughts you’d like to share, please leave a comment!

The problem with T-junctions is roundoff error. Roundoff might make the fill rule miss pixels between the polygons, and leave small gaps.
This is entirely dependent on your hardware. Testing it on just one card is not enough to conclude it is safe. Probably modern cards do less rounding and handle this better, but if you ran it on older hardware, you might see problems.
The T-Junction aliasing only shows up at extreme angles, and to be honest, isn’t that noticeable. But it is there, and does create some slightly more grainy terrain (such as what one would see in the distance in minecraft)
This shit happens to me al the time. Try an intel card, with floating point values on the meshes, further away from 0.
Ok, I’m convinced that there is something to the whole T-junction thing, but it is pretty difficult to replicate consistently. If anyone has a good method for generically reproducing this issue, I’d appreciate any suggestions.
The t-junction issue is mitigated in Minecraft-like engines because of the nature of the data. Every triangle is either parallel or perpendicular to their neighbor and each vertex is at a whole number.
You can try to force gaps to appear by drawing far from the origin (as vanitylicenseplaten suggested) and rotating the mesh. Essentially that will force rounding errors on the video card. Cheaper video cards use smaller floating point numbers in hardware so they’ll show up more often.
Even then, I doubt it’ll be that noticeable. If you were writing a terrain engine with smooth hills the t-junction problem is very noticeable. I wouldn’t worry about it if I were you.
Cracks in T-Junctions generally appear due to the hardware snapping vertices to sub-pixel locations. The less sub-pixel accuracy the more a crack is likely to appear. The PS1 for example would snap each vert to the pixel center at low screen resolutions and T-Junctions were rife on subdivided Polys (to counter the affine texture mapping). Modern graphics cards probably store the line equations for triangle edges during rasterization at very high precision making cracks very rare.
The best way to test for T-Junctions is to manually quantize positions to pixel centres inside the vertex shader though you could easily screw up the clipping if not careful.
First, thanks for this new post. Really interesting and simple yet again.
Second, could you tell me by which voodoo magic I can zoom in or out in the demos? I’d find it quite useful.
I’m interested in implementing greedy or even monotone meshing for my current project, but I have to say it’s generally inefficient for random access read-writes. On my mid-end machine, the meshing time is roughly 30 to 45ms, even after spending much, much time optimizing in all the possible ways I could think of. There simply are too many voxels to traverse to remesh a page (“chunk”) at each voxel modification.
This is why naive meshing is best for these practical implementations. When meshing, I store the results in a hashmap of a coordinate (XYZ) to a list of quads. Albeit longer to store, this meshing only occurs once for the chunk. Then, when a voxel gets added or removed, only the 6 neighbouring voxels are remeshed, which is virtually instantaneous. It’s about 36 (6 neighbours * their own 6 neighbours) reads, which is nothing compared to the whole 32,768 voxels in a normal, Minecraft sized chunk.
I believe this is why Minecraft never used greedy or monotone meshing (as I said in my previous comment, I tested myself with the latest client and a wireframe view). If a voxel got modified, it’d be impossible (or at least impractical) to determine which quads to remake.
However, if the memory costs are low enough (and they should be), one of the best compromises could be to store a greedy mesh in memory for each surrounding chunk that the player doesn’t occupy (or isn’t close to), along with the naive mesh. When active, a chunk would use its naive mesh. When in the background, exempt from possible modifications (if we abide by that claim, that a far away chunk cannot be modified), it could use the greedy or monotone mesh to spare some FPS.
But as Minecraft has proved, for 1 cubic meter cubes, this approach is not necessary. The bottleneck is not the amount of triangles rendered by the GPU, but the amount of calculations made by the CPU, and unfortunately triangle optimization is more CPU costly than GPU efficient. If, for any reason, smaller cubes were to be used, triangle optimization as shown in your series would perhaps be necessary. This is the case for my project, so I’ll eventually get back to you with results. I’m also using an algorithm to average far away voxels into bigger cubes, since their resolution is not crucial.
Thanks again for your continued interest! I really appreciate the feedback.
To answer your first (easy) question, you can zoom in and out by holding down middle mouse. (I am using the default camera controls for three.js, and kind of stupidly forgot to put onscreen instructions for it!)
Now the question of how to make greedy meshing faster is a bit trickier. One first optimization is that you only need to do 3 sweeps over the volume. The second point is that you can preallocate a buffer to keep track of the type of cells. Instead of using a hash map to track quads, you can just zero out the voxels once you’ve meshed them. This sounds at first like it is a bit less efficient, however you have to do at least this much work anyway, and it turns out that accessing a small array is typically much faster than maintaining a more sophisticated data structure. Of course this will probably not scale as well as your chunks get bigger. To see how this works in practice, you can look at the javascript code in the demo. Hopefully it is not too obtuse, but I shamefully admit that it is not the most legible. In my defense, it is Javascript.
Of course the biggest possible pay off is to just change your map data structure, but the analysis is more complicated. You quickly get a combinatorial explosion where the number of possiblities is (#data structures) x (#meshing algorithms). One thing that ought to help is run length encoding. Run length encoding should speed up meshing (especially for the monotone method) along axial directions, but it is awkward along the non-axis aligned components. To fix this, I can think of two options:
1. Simply store 3 run length encoded meshes, one sorted by x, another by y and another by z. This triples the storage, but if you are using run length encoding it might not be too bad.
2. Alternatively, only do mesh optimization along a single axis and just mesh the other dimensions naively.
Even if you only do one run length encoding, you can still speed up the meshing and reduce the cost of evaluating it by meshing into strips. I actually used this technique for an old javascript minecraft demo, and it is very fast though I’ve not gone through the necessary rigor to compare it to greedy meshing or related techniques. The downside is that the meshes you get just aren’t as good as either the greedy meshes or monotone meshes.
There are also other benefits to run length encoding as well, like faster lighting calculations and overall speed ups caused by reducing the amount of memory you have to move around.
Of course I still believe that it is possible to do even better. If you could dynamically maintain a 3D greedy mesh, then not only could you use it to extract boundary faces quickly, but it could also drastically reduce the amount of memory consumed (and would therefore be even faster). Sadly, I don’t yet see how to implement such a thing.
I think I wasn’t clear enough, sorry – even the naive meshing is too long. Actually, greedy is faster than naive, for some reason. Your demo shows it well when you switch the FPS view to the frame time view, at least on my machine. A spike is shown, for stupid, naive, greedy, and even monotone.
I’m fairly happy with my technique as of now though, and the memory storage isn’t horribly high. But I don’t think I was clear on that either. My process goes in 3 steps:
1. Generate the quad cloud (a hashmap of 3D coordinates to a list of quads) from the voxel cloud (long, because every voxel is traversed).
2. Generate the mesh from the quad cloud by flattening the hashmap to keep only one big list of quads (extremely fast, does not impact framerate).
3. On modification, say block removal for instance:
-Null out the voxel in the voxel cloud
-Remove the hashmap entry for the voxel coordinate in the quad cloud
-Regenerate the quad cloud entries for the voxel and its neighbours
-Generate the mesh (step 2)
Hello there, first of all, thanks a lot for your explanation and example code/demo about different techniques for minecraft-like engines.
So far I have ported the greedy code from js to c++ (I can post it here if you are interested). It works really great, there still some parts of the algorithm I doesn’t understand, probably the reason for the above question.
In your demo, the Hilly Terrain is a good representation of a “chunk” in a minecraft-like game, but, as it is shown there, the “walls” ( http://imagebin.org/240680 ) of the chunk are visible, for this demo I can see it as something expected, but pretend you have a grid of chunks,then there will be a lot of cubes that will be rendered but will not be visible, the obvious optimization for it is simple not add these cube vertices to the mesh,
I have an implementation of this optimization using the culled algorithm ( http://imagebin.org/240684 ), basically when I’m in some boundary of the chunk I check the next position from the neightbor chunk, let’s say my chunks are 16x16x16, so when I’m in position x 15, I will see if there is a valid cube from the neighbor in position x 0 to decide if I will draw the cube or not.
So, finally, my question is, how can I implement this kind of optimization using the greedy method?
Thanks a lot!
I’ve done some testing to complement my previous post, basically I’ve generated an terrain using the culled and greedy algorithms, culled with the “wall” pixels optimizations and the greedy without, as you can see in the above images, the culled implementation actually renders less triangles than the greedy one, exclusivelly because of the above optimization.
Culled: http://imagebin.org/240796
Greedy: http://imagebin.org/240795
It looks to me that such optimization is a must have to use the greedy algorithm in such a scenary.
Thanks!
I’d love to see the c++ version if thats possible. I’m still learning quite a bit about all of this. Thanks
I don’t have a c++ version, but porting it shouldn’t be too hard since I am not doing anything too crazy in JavaScript. If you want to try go ahead and give it a shot.
There you go: http://pastebin.com/zMGXhUcp
🙂
thanks, looks cool, still studying it. 🙂
I guess I’m late to the party / beating a dead horse etc, but actually had to depart from using the greedy strategy because of visible artifacts from the T-junctions / round-off errors. The artifacts were not at all visible in light areas, but darker areas would get small white artifacts, both on nvidia and intel cards. I made a little page back then to better understand the problem: http://folk.ntnu.no/hakonomd/three/ The seam along the shorter face and the middle face displays random white pixels, while the seam between the two equal length faces display no artifacts.
As far as I can understand, any engine with lighting / shadows would experience this in the darker areas if they are using the greedy strategy. Have people solved this in some way?
Late to the party too, but same here…
Anyone figuring out a way around the t-junctions/seams would be really helpful. It’s hard to get much information on this issue. Changing the background/skybox depending on your location would make the artifacts less noticeable – but other than that, I’ve come up with nothing.
Thanks for the great article! I was implementing my own reduction algorithm based on simply grouping strips and was adding support for extending the strips to create the large rectangles. That’s when I came across this article.
Your implementation was a bit more elegant than mine (which somehow grew to include some custom ‘BlockGroup’ classes and all sorts of nonsense). So I spent an afternoon to really understand your code and re-implement it in C#.
One minor little ‘gotcha’ that other’s might run into if they decide to port your code; on line 68 where you calculate the width of the strip, you are indexing the mask BEFORE you check if the index is out of range. You get away with this in Javascript because you’re using the “===” operator which checks for same type first, but in other languages, it will just crash. Just change this:
for(w=1; c === mask[n+w] && i+w<dims[u]; ++w) {}
To this:
for(w=1; i+w<dims[u] && c === mask[n+w]; ++w) {}
Thank you so much for the great bit of code! I had fun reading it and I'll admit it was a good challenge to really 'grok' what it's doing.
Kind regards.
I would love to see your C# implementation if you are willing to share it.
The pixel bleeding does not only appear with T-junction. It also appears in Mono as this screenshot shows: http://i.imgur.com/PF7S8wl.png
I’ve solves this in two ways now, the second one runs much, much faster but the triangles are not as evenly distributed. Both approaches are a bit of work to implement.
(1) You can use poly2tri (google it) and treat the voxel outline as your polygon (this is a bit tricky as holes must not be connected to each other or the outline for input to poly2tri, point doubling and smart interpolation helps here).
(2) Alternatively you can modify the mono algorithm to “add triangles”. This can be done *really* efficient on the fly. Well implemented the run time is not much slower than T-junction (and crazy in speed!)
In both cases the triangle count will be n-2 (where n is the number of vertices). However poly2tri does distribute the triangles more evenly, so if you don’t care about speed it might be the better solution.
PS: If you have questions about this, my twitter is @whiteflux
Scratch the n-2. That is incorrect for the general case. Modified mono seems to produce more triangles in general.
I’ve finally finished my first blog post on this topic. The second one will come very soon!
http://blackflux.wordpress.com/2014/02/23/meshing-in-voxel-engines-part-1/
Great! I’m excited to see what you come up with next!
Hi, thank you for your great articles.
So far I’ve ported your greedy mesh implementation to both C++ and Java, using the actual WebGL demo code (http://mikolalysenko.github.io/MinecraftMeshes2/js/greedy.js) as a source. What I noticed in Java is that – besides the issue Kiaran Ritchie reported above, thanks for that – the IntelliJ code analysis reports the assignment “c = -c;” in line 91 as redundant because “c” isn’t used afterwards anymore.
I now wonder if that’s just a left-over, or if there’s something about Javascript I don’t comprehend and didn’t port properly.
Oh never mind, found the reference to “c” in the faces.push() call. I didn’t use that one yet in my port.
The way I understood it, these methods create few primitives, but a lot of areas that are behind one another from the cameras perspective, except for naive culling. Since fillrate is typically a bigger problem than vertex processing, isn’t this the opposite of the trade-off you are interested in (less area, more vertices).
Maybe I missed something, but I guess culling and meshing the result is a better approach, even if it results in more vertices and primitives.
Trouble with that approach is that you would have to recalculate it every time the camera moves; i.e. pretty much every frame.
Anyone happen to have a C/C++ port of the monotone meshing? I’ve been trying to port it myself but so far it’s not going too well.
I even have the errors in your Demo – also in my C++ Port of the greedy algorithm. Any suggestions?
https://www.imgpaste.net/image/E6gc6
Just in case…
GL_VERSION: 3.0 Mesa 17.2.6
GL_RENDERER: AMD Radeon (TM) RX 480 Graphics (AMD POLARIS10 / DRM 3.19.0 / 4.14.5-1-ARCH, LLVM 5.0.0)
GL_VENDOR: X.Org
And by the way, a great website, keep on! 🙂
hello!! 10 years later! are someone still working or have made a port to c/c++ or c#? i cant figure out the math 😦
One way to fix T-junctions is to generate extra triangles to fill the seam. Imagine a T-junction in the middle of a big quad. Vertices A and B are in the middle of opposite edges of the quad and vertex C is in the middle of the quad forming the intersection of the T. Add the triangle [A,B,C] to fill any gaps. It will usually be degenerate and get culled after the vertex shader, however occasionally it will lend a few pixels to the framebuffer.