To briefly recap, our goal is to render large volumetric environments. For the sake of both efficiency and image quality, we want to introduce some form of level of detail simplification for distant geometry. Last time, we discussed two general approaches to level of detail — surface and volumetric — focusing primarily on the former. Though volumetric terrain is not exactly the same as height-map based terrain, we can draw an imperfect analogy between these two problems and the two most popular techniques for 2D terrain rendering: ROAM and geometry clipmaps.
ROAM vs. Clip Maps
ROAM, or Realtime Optimally Adapting Meshes, is in many ways the height-field equivalent of surface based simplification. In fact, ROAM is secretly just the simplification envelopes algorithm applied to large regular grids! For any viewing configuration and triangle budget, ROAM computes an optimally simplified mesh in this sense. This mesh is basically as good as it gets, modulo some twiddle factors with the error metric. The fact that ROAM produces nicely optimized meshes made it very popular in the late nineties — an era when rasterization was much more expensive than GPU bandwidth.
The downside to ROAM is that when your camera moves, this finely tuned mesh needs to be recalculated (though the changes may not be too big if your camera motion is small enough). The cost of these updates means that you need to send a lot of geometry and draw calls down the GPU pipeline each frame, and that your CPU has to burn many cycles recalculating and updating the mesh. Though the approach of “build the best mesh possible” once made a lot of sense, as GPUs got faster and faster, eventually leaving CPUs in the dust, the rasterization vs bandwidth tradeoff shifted dramatically in the other direction, eventually making other strategies more competitive.
Geometry clipmaps are the modern replacement for ROAM, and are designed with the reality of GPU hardware in mind. Instead of trying to fully optimize the terrain mesh, clipmaps instead approximate different levels of detail by resampling the heightfield. That is, at all levels of detail the terrain mesh is always rendered as a uniform grid, it’s just that as we go farther away from the camera it becomes less dense. While geometry clipmaps produce lower quality meshes than ROAM, they make up for this short-coming by using much less GPU bandwidth. The clever idea behind this technique is to update the different levels of detail using a rolling hierarchy of toroidal buffers. This technique was first described in the following paper:
C. Tanner, C. Migdal, M. Jones. (1997) “The Clipmap: A Virtual Mipmap” SIGGRAPH 98
The first mention of using clipmaps for GPU accelerated terrain appears to be an old article on flipcode by Willem de Boer from late 2000 — though the credit for popularizing the idea usually goes to the following two papers, which rediscovered the technique some years later:
F. Losasso, H. Hoppe. (2004) “Geometry clipmaps: Terrain rendering using nested regular grids” SIGGRAPH 2004
A. Asrivatham, H. Hoppe. (2005) “Terrain rendering using GPU-based geometry clip-maps” GPU Gems 2
In practice, clipmaps turn out to be much faster than ROAM for rendering large terrains at higher qualities. In fact, clipmaps have been so successful for terrain rendering that today the use of ROAM has all but vanished. I don’t think too many graphics programmers lament its obsolescence. ROAM was a lot more complicated, and had a bad reputation for being very difficult to implement and debug. Clipmaps on the other hand are simple enough that you can get a basic implementation up and running in a single sitting (assuming you already have a decent graphics framework to start from).
Clipmaps for Isosurfaces
Given that clipmaps work so well for heightfields, it seems intuitive that the same approach might work for large isosurfaces as well. Indeed, I am aware of at least a couple of different attempts to do this, but they are all somewhat obscure and poorly documented:
- Genova Terrain Engine: As far as I know, Peter Venis’ Genova terrain engine is one of the first programs capable of rendering large volumetric terrain in real time. What is more impressive is that it did all of this in real-time back in 2001 on commodity graphics hardware! During the time when flipcode was still active, this project was quite famous:

Unfortunately, there is not much information available on this project. The original website is now defunct, and the author appears to have vanished off the face of the internet, leaving little written down. All that remains are a few pages left in the internet archive, and some screenshots. However, from what little information we do have, we could draw a few probable conclusions:
- Genova probably uses surface nets to extract the isosurface mesh.
- It also supports some form of level of detail, probably volumetric.
- Internally it uses some form of lossless compression (probably run-length encoding).
Beyond that, it is difficult to say much else. It is quite a shame that the author never published these results, as it would be interesting to learn how Genova actually works.
UPDATE: I receive an email from Peter saying that he has put the website for Project Genova back online and that the correct name for the project is now Genova. He also says that he has written another volumetric terrain engine in the intervening years, so stay tuned to see what else he has in store.
- HVox Terrain Engine: Sven Forstmann has been active on flipcode and gamedev.net for many years, and created several voxel rendering engines. In particular, his HVox engine, that he released way back in 2004 is quite interesting:

It is hard to find details about this algorithm, but at least it seems like some stuff did ultimately get written up about it (though it is not easily accessible). Like the Genova terrain engine, it seems that HVox uses some combination of surface nets and geometry clip maps, though I am not fully confident about this point. The major details seem to be contained in an unpublished technical report, that I can’t figure out how to download. (If anyone out there can get a copy or knows how to contact Forstmann, I’d love to read what he has written.) In the end, I suspect that some of the technology here may be similar to Genova, but as the details about either of them are sparse, it is difficult to draw any direct comparisons.
- TransVoxel: The TransVoxel algorithm was first described in Eric Lengyel‘s PhD Thesis, as an extension of marching cubes to deal with the additional special cases arising from the transition between two levels of detail:

Unlike the previous papers, TransVoxel is quite well documented. It has also been commercially developed by Lengyel’s company, Terathon Studios, in the C4 engine. Several alternative implementations based on his look up tables exist, like the PolyVox terrain engine.
The main conclusion to draw from all this is that clip maps are probably a viable approach to dealing with volumetric terrain. However, unlike 2D fields, 3D level of detail is quite a bit more complicated. Most obviously, the data is an order of magnitude larger, which places much stricter performance demands on volumetric renderer compared to height-field terrain. However, as these examples show the overhead is managable, and you can make all of this work — even on hardware that is more than a decade old!
Sampling Volumes
But while clip map terrain may be technically feasible, there is a more fundamental question lurking in the background. That is:
How do we downsample volumetric terrain?
Clearly we need to resolve this basic issue before we can go off and try to extend clipmaps to volumes. In the rest of this article, we’ll look at some different techniques for resampling volume data. Unfortunately, I still don’t know of a good way to solve this problem. But I do know a few things which don’t work, and I think I have some good explanations of what goes wrong. I’ve also found a few methods that are less bad than others, but I none of these are completely satisfactory (at least compared to the surface based simplification we discussed last time).
Nearest Neighbors
The first – and by far the simplest – method for downsampling a volume is to just do nearest neighbor down sampling. That is, given a 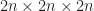

Here is a graphic illustrating this process:

The idea is that we throw out all the blue samples and keep only the red samples to form a new volume that is 1/8th the size (ie 1/2 in each dimension). Nearest neighbor filtering has a number of advantages: it’s simple, fast, and gives surprisingly good results. In fact, this is the method used by the TransVoxel algorithm for downsampling terrain. Here are the results of applying of applying 8x nearest neighbor filtering to a torus:


The results aren’t bad for a 512x reduction in the size of the data. However, there are some serious problems with nearest neighbor sampling. The most obvious issue is that nearest neighbor sampling can miss thin features. For example, suppose that we had a large, flat wall in the distance. Then if we downsample our volume using nearest neighbor filtering, it will just pop into existence out of nowhere when we transition between two levels of detail! What a mess!

Linear Sampling
Taking a cue from image processing, one intuitive way we might try to improve upon nearest neighbor sampling would be to try forming some weighted sum of the voxels around the point we are down sampling. After all, for texture filtering nearest neighbor sampling is often considered one of the `worst’ methods for resampling an image; it produces blocky pixellated images. Linear filtering on the other hand gives smoother results, and has also been observed to work well with height field terrain. The general idea framework of linear sampling that we first convolve our high resolution image with some kernel, then we apply the same nearest neighbor sampling to project it to a lower resolution. Keeping with our previous conventions, let K be a
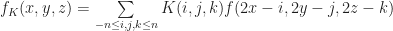
Clearly nearest neighbors is a special case of linear sampling, since we could just pick K to be a Dirac delta function. Other common choices for K include things like sinc functions, Gaussians or splines. There is a large body of literature in signal processing and sampling theory studying the different tradeoffs between these kernels. However in graphics one of the most popular choices is the simple `box’ or mean filter:
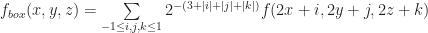
Box filters are nice because they are fast and produce pretty good results. The idea behind this filter is that it takes a weighted average of all the voxels centered around a particular base point:

The idea of applying linear interpolation to resampling volume data is pretty intuitive. After all, the signal processing approach has proven to be very effective in image processing and it is empirically demonstrated that it works for height field terrain mipmapping as well. One doesn’t have to look too hard to find plenty of references which describe the use of this techinque, for example:
T. He, L. Hong, A. Kaufman, A. Varshney, and S. Wang. (1995) “Voxel Based Object Simplification“. SIGGRAPH 95
But there is a problem with linearly resampling isosurfaces: it doesn’t work! For example, here are the results we get from applying 8x trilinear filtering to the same torus data set:

Ugh! That isn’t pretty. So what went wrong?
Why Linear Sampling Fails for Isosurfaces
While it is a widely observed phenomenon that linear sampling works for things like heightfields or opacity transfer functions, it is perhaps surprising that the same technique fails for isosurfaces. To illustrate what goes wrong, consider the following example. Let 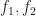

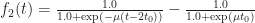
For example, if 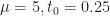

In this case, we plotted the steeper potential 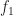
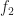
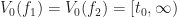
And so as potential functions, both
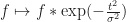
As we increase the radius of the Gaussian, 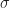

(If the GIF animation isn’t playing, try clicking on the image)
The steeper, red potential function’s sublevel set grows larger as we downsample, while the shallower blue sublevel set shrinks! Thus, we conclude that:
The result of downsampling an isosurface via linear filtering depends on the choice of potential function.
This means that if you downsample a volume in this way, aribtrarily weird things can (and usually will) happen. Small objects might become arbitrarily large as you transition from one level of detail to the next; large objects might shrink; and flat shapes can wiggle around like crazy. (As an exercise, see if you can construct some of these examples for the averaging filter.)
Clearly this situation is undesirable. Whatever downsampling method we pick should give the same results for the same isosurface – regardless of whatever potential function we happened to pick to represent it.
Rank Filters
Rank filters provide a partial solution to this problem. Instead of resampling by linearly filtering, they use rank functions instead. The general idea behind rank filters is that you take all the values of the function within a finite window, sort them, and select the kth highest value. One major benefit of taking a rank function is that it commutes with thresholding (or more generally any monotonic transformation of the potential function). This is not a complete solution to our problem of being potential function agnostic, but it is at least a little better than the linear situation. For example, two of the simplest rank filters are the max and min windows:
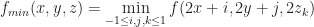

If we apply these to the same toroidal isosurface as we did before, we get the following results:


Left: The result of min filtering the torus, Right: The result of max filtering the torus. (Note: 4x downsampling was used instead of 8x)
That doesn’t look like a good resampling, and the fact that it breaks shouldn’t be too surprising: If we downsample by taking the min, then the isosurface should expand by an amount proportional to the radius of the window. Similarly, if we take a max the volume should shrink by a similar amount. The conclusion of all of this is that while min/max filters avoid the potential function ambiguity problem, they don’t preserve the shape of the isosurface and are therefore not an admissible method for down sampling.
So, the extremes of rank filtering don’t work, but what about middle? That is, suppose we downsample by taking the median the potential function within a window:
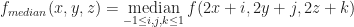
It’s frequently claimed that median filters tend to preserve sharp edges and contours in images, and so median filtering sounds like a good candidate for resampling isosurfaces. Unfortunately, the results are still not quite as good as nearest neighbor sampling:

Again, failure. So what happened? One clue can be found in the following paper:
E. Arias-Castro, D. Donoho. (2009) “Does median filtering truly preserve edges better than linear filtering?” Preprint available on Arxiv server
The main conclusion from that paper was that median filtering works well for small window sizes, but becomes progressively worse at matching contours as the windows grow larger. A proposed solution to the problem was to instead apply iterative linear filtering. However, for features which are on the order of about 1-2 window sizes, median filters do not preserve them. This is both good and bad, and can be seen from the examples in the demo (if you skip down to it). Generally the median filter looks ok, up until you get to a certain threshold, at which point the shape completely vanishes. It’s not really clear to me that this behavior is preferable to nearest neighbor filtering, but at least it is more consistent. Though what we would ultimately like to get is some more conservative resampling.
Morphological Filtering
In summary, median filtering can remove arbitrarily large thin features, which could be very important visually. While these are preserved by min filtering, the tradeoff is that taking the min causes the isosurface to expand as we decrease the level of detail. This situation is clearly bad, and it would be nice if we could just `shrink back’ the lower level of detail to the base surface. One crazy idea to do this is to just apply a max filter afterwards. This is in fact the essence of morphological simplification:
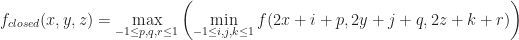
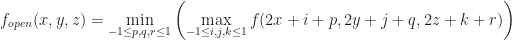
Surprisingly, this actually gives pretty good results. Here is what we get when we apply 8x closing to the same torus data set:

8x closing applied to the torus
This clever idea has been known for some time in the mathematical morphology community and is known as morphological sampling:
P. Maragos, (1985) “A unified theory of translation-invariant systems with applications to morphological analysis and coding of images” PhD. Thesis, Georgia Tech.
J.B.T.M Roerdink, (2002) “Comparison of morphological pyramids for multiresolution MIP volume rendering” Proc. of Data Visualization.
One remarkable property of using morphological closing for resampling a volume is that it preserves the Hausrdorff distance of the sublevel set. That is we can show that:
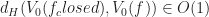
But there is a catch: In order to properly implement morphological sampling you have to change the way you calculate 0-crossings slightly. In particularly, you need to interpret your sample points not as just a grid of linearly interpolated values, but as a signed distance field. For example, if you have a pair of adjacent grid points, it is important that you also handle the case where the distance field passes through 0 without a sign change. This requires modifying the isosurface extraction code and is quite a bit of work. I’ve not yet implemented a correct version of this procedure, but this post has gone on long enough and so perhaps I will return to it next time.
Still, even without doing the corrected isosurface extraction, morphological sampling works quite well and it is interesting to compare the results.
Demo
Again, I made a WebGL demo to test all this stuff out:
Click here to try out the different filters in your browser
To handle boundary conditions, we just reflect the potential function (ie Neumann boundary conditions.) You can see the results of running the different volume simplification algorithms on some test algebraic surfaces. Here are a few pictures for comparison:
Sphere:








Left-to-right/top-top-bottom: Full resolution, 8x nearest neighbor, trilinear, min, max, median, closing, opening.
Asteroid:








Same order, 4x downsampling.
It should be clear that of all the methods we’ve surveyed, only three give reasonable results: nearest neighbors, (iterated) median filtering and morphological closing. All other methods we looked at failed for various reasons. Now let’s look at these three methods in more detail on a challenging example, namely Perlin noise:
Perlin Noise (full resolution):

| Resolution | Nearest Neighbor | Median | Morphological Closing |
| 1/2 |  |
 |
 |
| 1/4 |  |
 |
 |
| 1/8 |  |
 |
 |
In the end, even though our implementation of morphological closing is slightly `naive’ it still produces reasonable results. The deficiencies are more pronounced on the thin plate example, where my broken surface extractor accidentally removes all the tiny features! A correct implementation should theoretically preserve the plates, though fixing these problems is likely going to require a lot more work.
Conclusion
While it is feasible to do efficient volumetric clip-map based terrain, level-of-detail simplification is incredibly difficult. Looking back at all the headaches associated with getting level of detail “right” for volumes really makes you appreciate how nice surface simplification is, and how valuable it can be to have a good theory. Unfortunately, there still seems to be room for improvement in this area. It still isn’t clear to me if there is a good solution to these problems, and I still haven’t found a silver bullet. None of the volumetric techniques are yet as sophisticated as their surface based analogs, which is quite a shame.
We also investigated three plausible solutions to this problem: nearest neighbors, median filtering and morphological sampling. The main problem with nearest neighbors and median filtering is that they can miss small features. In the case of median filtering, this is gauranteed to happen if the features are below the size of the window, while for nearest neighbors it is merely random. Morphological sampling, on the other hand, always preserves the gross appearance of the isosurface. However, it does this at great computational expense, requiring at least 25x the number of memory accesses. Of course this may be a reasonable trade off, since it is (at least in a correct implementation) less likely to suffer from popping artefacts. In the end I think you could make a reasonable case for using either nearest neighbor or morphological sampling, while the merits of median filtering seem much less clear.
Now returning to the bigger question of surface vs. volumetric methods for terrain simplification, the situation still seems quite murky. For static terrain at least, surface simplification seems like it may just be the best option, since the cost of generating various levels of detail can be paid offline. This idea has been successfully implemented by Miguel Cepero, and is documented on his blog. For dynamic terrain, a clip map approach may very well be more performant, at least judging by the works we surveyed today, but what is less clear is if the level of detail transitions can be handled as seamlessly as in the height field case.

Awesome article, very well structured and written thank you!
Only one small thing I feel is missing. For the comparison I’d like to see textured examples. Not for all mind you, only the asteroid maybe, just to gauge the visual effect / artifacts the algorithms produce in a “real” scene. Other than that the pictures are very well done and show how the algorithm works perfectly.
Thank you, and .. um… more please 🙂
Your blog is amazing. I recently started an implementation of marching cubes and found LOD simplification to be pretty much impossible. Thanks for the thoroughly informative post.
Incredibly useful blog post – it has me itching to do some graphics programming again.
If you’re not already familiar with it, you might be interested in the work done by Miguel Cepero for his procedural world tools: http://procworld.blogspot.com/
Hey actually links a blog by Miguel Cepero at the bottom. Definitely a source of great information as well.
Just wanted to say that your articles are so great. You explain these complex topics very well, and those webgl demos are awesome. This article in particular was very useful to me for my project. Well done!
Do you have the js code posted in git for morphological filtering? I’d love to see how that’s done if possible.
Not in a separate repository, but you can see all the code in that demo on my main repository at https://github.com/mikolalysenko/mikolalysenko.github.com/tree/master/LevelOfDetail
You also say in the article that the implementation is naive and that a correct implementation would preserve the thin plates. Do you know what is needed for a correct implementation?
I should give a few more details, I’m pretty much doing exactly what this article is focusing on, and am producing a large chunk of density values, and filtering them down using your MF method. Like you have stated, it works pretty well, but it causes some discontinuities when going from a lower to higher LOD. I can generate seams but if the data on either end is very different, you will not be able to generate them. I will post a picture when I can get to my computer.
Yeah, so what you need to do is modify the way you extract the contour slightly. The key idea is that if you have a signed distance field to the surface and say you know this distance at the two vertices along the edge is +0.2 and maybe +0.3, then you know that there should be at least a pair of crossings along that edge. So what you need to do then is modify the contouring algorithm to extract multiple surfaces for each connected component. This is how manifold dual contouring works:
Click to access dualsimp_tvcg.pdf
Once I get some breathing room I will do a write up on the idea, but you can find most of the details in that paper.
I think perhaps my issue has to do with the filtering, I just have a hilly area, and that’s it, there should never be a case where an edge has multiple crossings. The issue you describe is definitely something I need to look at, but that has more to do with when you have multiple surfaces very close together. I’ll post a picture in a few hours.
Also to expand on that article, it looks like they are generating everything at the finest level of detail, and then collapsing and clustering based on a number of rules. What I am doing is generating all the density at the finest level, immediately filtering it morphologically, and then running DC over the filtered area. Does adaptive manifold DC require that you need to run these tests before filtering? Implying that you can’t just filter everything?
Sorry to keep pelting you with these questions. Had one more. if you have a function f(x,y,z) that returns the density at that point, is there a formula to get the 8x(or nx) morphological sample, just at a certain point? I’m not sure if you can just get the min & max of all the points surrounding the point in questing, in a certain radius, or if you need to do a little recursion to take morphological samples over and over again. Thank you again for all the help so far!