Large voxel terrains may contain millions of polygons. Rendering such terrains at a uniform scale is both inefficient and can lead to aliasing of distant objects. As a result, many game engines choose to implement some form of level of detail based rendering, so that distant terrain is rendered with less geometry.
In this post, I’ll talk about a simple technique based on vertex clustering with some optimizations to improve seam handling. The specific ideas in this article are applied to Minecraft-like blocky terrain using the same clustering/sorting scheme as POP buffers.
M. Limper, Y. Jung, J. Behr, M. Alexa: “The POP Buffer: Rapid Progressive Clustering by Geometry Quantization“, Computer Graphics Forum (Proceedings of Pacific Graphics 2013)
Review of POP buffers
Progressively Ordered Primitive (POP) buffers are a special case of vertex clustering, where for each level of detail we round the vertices down to the previous power of two. The cool thing about them is that unlike other level of detail methods, they are implicit, which means that we don’t have to store multiple meshes for each level detail on the GPU.
When any two vertices of a cell are rounded to the same point (in other words, an edge collapse), then we delete that cell from that level of detail. This can be illustrated in the following diagram:

Suppose that each vertex 
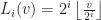
This determines a filtration on the vertices,

Which extends to triangles 

And so it follows that,
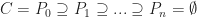
Each of the sets 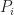

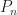


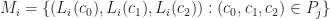
Using this property, we can encode the different levels of detail by sorting the primitives of the mesh from coarse-to-fine and storing a table of offsets:

To render the mesh at any level of detail we can adjust the vertex count, and round the vertices in the shader.
Building POP buffers
To construct the POP buffer, we need to sort the quads and count how many quads are in each LOD. This is an ideal place to use counting sort, which we can do in-place in O(n) time, illustrated in the following psuedo-code:
// Assume MAX_LOD is the total number of levels of detail
// quadLOD(...) computes the level of detail for a quad
function sortByLOD (quads) {
const buckets = (new Array(MAX_LOD)).fill(0)
// count number of quads in each LOD
for (let i = 0; i < quads.length; ++i) {
buckets[quadLOD(quads[i])] += 1
}
// compute prefix sum
let t = 0;
for (let i = 0; i < MAX_LOD; ++i) {
const b = buckets[i]
buckets[i] = t
t += b
}
// partition quads across each LOD
for (let i = quads.length - 1; i >= 0; --i) {
while (true) {
const q = quads[i]
const lod = quadLOD(q)
const ptr = buckets[lod]
if (i < ptr) {
break;
}
quads[i] = quads[ptr]
quads[ptr] = q
buckets[lod] += 1
}
}
// buckets now contains the prefixes for each LOD
return buckets
}
The quadLOD() helper function returns the coarsest level of detail where a quad is non-degenerate. If each quad is an integer unit square (i.e. not the output from a greedy mesh), then we can take the smallest corner and compute the quad LOD in constant time using a call to count-trailing zeroes. For general quads, the situation is a bit more involved.
LOD computation
For a general axis-aligned quad, we can compute the level of detail by taking the minimum level of detail along each axis. So it then suffices to consider the case of one interval, where the level of detail can be computed by brute force using the following algorithm:
function intervalLOD (lo, hi) {
for (let i = 0; i <= 32; ++i) {
if ((lo >> i) === (hi >> i)) {
return i
}
}
}
We can simplify this if our platform supports a fast count-leading-zeroes operation:
function intervalLOD (lo, hi) {
return countLeadingZeroes(lo ^ hi)
}
Squashed faces
The last thing to consider is that when we are collapsing faces we can end up with over drawing due to rounding multiple faces to the same level. We can remove these squashed faces by doing one final pass over the face array and moving these squashed faces up to the next level of detail. This step is not required but can improve performance if the rendering is fragment processing limited.
Geomorphing, seams and stable rounding
In a voxel engine we need to handle level of detail transitions between adjacent chunks. Transitions occur when we switch from one level of detail to another abruptly, giving a discontinuity. These can edges be hidden using skirts or transition seams at the expense of greater implementation complexity or increased drawing overhead.
In POP buffers, we can avoid the discontinuity by making the level of detail transition continuous, similar to 2D terrain techniques like ClipMaps or CLOD. Observe that we can interpolate between two levels of detail using vertex morphing,
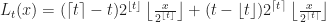
In the original POP buffer paper, they proposed a simple logarithmic model for selecting the LOD parameter as a function of the vertex coordinate 
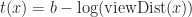
Where 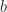
The authors of the original POP buffer paper proposed modifying their algorithm to place vertices along the boundary at the lowest level of detail. This removes any cracks in the geometry, but increases LOD generation time and the size of the geometry.
Instead we can solve this problem using a stable version of LOD rounding. Let 


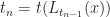
In practice 2-3 iterations is usually sufficient to get a stable solution for most vertices. This iteration can be implemented in a vertex shader and unrolled, giving a fast seamless level of detail selection.
As an aside, this construction seems fairly generic. The moral of the story is really that if we have geomorphing, then we don’t need to implement seams or skirts to get crack-free LOD.
World space texture coordinates
Finally, the last issue we need to think about are texture coordinates. We can reuse the same texturing idea from greedy meshing. For more info see the previous post.

Sea of Memes tried this many a Winter ago and found that just doesn’t read very well. It looks like a block that’s not far away.
http://www.sea-of-memes.com/LetsCode64/LetsCode64.html
This is what they did instead
http://www.sea-of-memes.com/LetsCode67/LetsCode67.html
But there’s still erasure of details. LOD systems for voxel games (and really, any game with user-created content) remain a bugbear.
What may work instead is a LOD that creates a “curved” model, like marching cubes, but unlike the work done so far, projects details outwards from the model in a way that matches both texture and lighting.
I’m not explaining this well — I comment in the hopes that I am explaining it just well enough.
I haven’t tried it, but I mean to, someday.
One key difference between this approach and Sea of Memes is that this operates on meshes and transitions smoothly, so you don’t get thin features disappearing. I think it should also be much faster and simpler to implement, but I don’t have access to his code so it is hard to make a direct comparison.
This is quite a longshot since this blog is several years old, but I would love to take a closer look at how you implemented this (especially the geomorphing/crack issue). Do you happen to have a repro of this available to look st?
Not any more. Some of this code was eventually shipped in https://box3.dao3.fun/