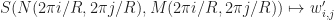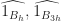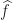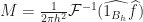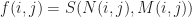(This is the sequel to the following post on SmoothLife. For background information go there, or read Stephan Rafler’s paper on SmoothLife here.)
Last time, we talked about an interesting generalization of Conway’s Game of Life and walked through the details of how it was derived, and investigated some strategies for discretizing it. Today, let’s go even further and finally come to the subject discussed in the title: Conway’s Game of Life for curved surfaces!
Quick Review: SmoothLife
To understand how this works, let’s first review Rafler’s equations for SmoothLife. Recall that 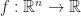

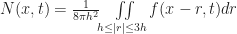
And that the next state of f is computed via the update rule:
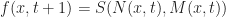
Where:
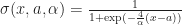
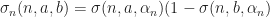
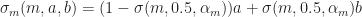
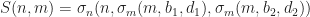
And we have 6 (or maybe 7, depending on how you count) parameters that determine the behavior of the automata:
: The fraction of living neighbors required for a cell to stay alive (typically
).
: The fraction of living neighbors required for a cell to be born (typically
).
: The transition smoothness from live to dead (arbitrary, but Rafler uses
).
: Transition smoothness from interval boundary (again, arbitrary but usually about
).
: The size of the effective neighborhood (this is a simulation dependent scale parameter, and should not effect the asymptotic behavior of the system).
Non-Euclidean Geometry
Looking at the above equations, the only place where geometry comes into the picture is in the computation of the M and N fields. So it seems reasonable that if we could define the neighborhoods in some more generic way, then we could obtain a generalization of the above equations. Indeed, a similar idea was proposed in Rafler’s original work to extend SmoothLife to spherical domains; but why should we stop there?
Geodesic Distance
The basic idea behind all of this is that we want to generalize the concept of a sphere to include curved surfaces. Recall the usual definition of a sphere is that it is the set of all points within some distance of a given point. To extend this concept to surfaces, we merely have to change our definition of distance somewhat. This proceeds in two steps.
First, think about how the distance between two points is defined. In ordinary Euclidean geometry, it is defined using the Pythagorean theorem. That is if we fix a Cartesian coordinate system the distance between a pair of points 
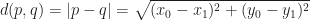
But this isn’t the only way we could define this distance. While the above formula is pretty easy to calculate, it by far not the only way such a distance could be defined. Another method is that we can formulate the path length variationally. That is we describe the distance between points p and q as a type of optimization problem; that is it is the arc length of the shortest path connecting the two points:
![d(p,q) = \min \limits_{f : [0,1] \to \mathbb{R}^2\\f(0)=p, f(1)=q} \int \limits_0^1 |\partial_t f(t)| dt](https://s0.wp.com/latex.php?latex=d%28p%2Cq%29+%3D+%5Cmin+%5Climits_%7Bf+%3A+%5B0%2C1%5D+%5Cto+%5Cmathbb%7BR%7D%5E2%5C%5Cf%280%29%3Dp%2C+f%281%29%3Dq%7D+%5Cint+%5Climits_0%5E1+%7C%5Cpartial_t+f%28t%29%7C+dt&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
At a glance this second statement may seem a bit silly. After all, solving an infinite dimensional optimization problem is much harder than just subtracting and squaring a few numbers. There is also something about the defining Euclidean distance in terms of arclength that seems viciously circular — since the definition of arclength is basically an infinitesimal version of the above equation — but please try not to worry about that too much:

Instead, the main advantage of working in the variational formulation is that it becomes possible to define distances in spaces where the shortest path between two points is no longer a straight line, as is the case on the surface of the Earth for example:

Of course to define the arclength for something like a curve along a sphere, we need a little extra information. Looking at the definition of arclength, the missing ingredient is that we need some way to measure the length of a tangent vector. The most common way to do this is to introduce what is known as a Riemannian metric, and the data it stores is precisely that! Given a smooth manifold 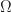

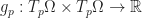
![f : [0,1] \to M](https://s0.wp.com/latex.php?latex=f+%3A+%5B0%2C1%5D+%5Cto+M&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
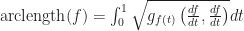
Armed with this new generalization arclength, it is now pretty clear how we should define the distance between points on a Riemannian manifold (that is any differentiable manifold equipped with a Riemannian metric). Namely, it is:
![d(p,q)=\min \limits_{\begin{array}{c} f : [0,1] \to M, \\ f(0) = p, f(1)=q\end{array}} \int_0^1 \sqrt{g_{f(t)} \left( \frac{d f}{dt}, \frac{d f}{dt} \right)} dt](https://s0.wp.com/latex.php?latex=d%28p%2Cq%29%3D%5Cmin+%5Climits_%7B%5Cbegin%7Barray%7D%7Bc%7D+f+%3A+%5B0%2C1%5D+%5Cto+M%2C+%5C%5C+f%280%29+%3D+p%2C+f%281%29%3Dq%5Cend%7Barray%7D%7D+%5Cint_0%5E1+%5Csqrt%7Bg_%7Bf%28t%29%7D+%5Cleft%28+%5Cfrac%7Bd+f%7D%7Bdt%7D%2C+%5Cfrac%7Bd+f%7D%7Bdt%7D+%5Cright%29%7D+dt&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
This is called the geodesic distance between p and q, after the concept of a geodesic which is a fancy name for `the shortest path between two points’. The fact that concatenation of paths is associative implies that geodesic distance satisfies the triangle inequality, and so it is technically a metric. The fact that our metric is allowed to vary from point to point allows us to handle much more flexible topologies and and surfaces. For example, parallel or offset curves on a Riemannian manifold may not be straight lines. This leads to violations of Euclid’s parallel postulate and so the study of Riemannian manifolds is sometimes called non-Euclidean geometry. (It also has a few famous applications in physics!)
Geodesic Balls
Now that we have a definition of distance that works for any surface (with a Riemannian metric), let’s apply it to Rafler’s equations. I claim that all we need to do is replace the spherical neighborhoods in SmoothLife with some suitably constructed geodesic neighborhoods. In particular, we can define these neighborhoods to be balls of some appropriate radius. Given a point p, we define the geodesic ball of radius h centered at p to be the set of all points within distance at most h of p:
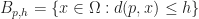
Which naturally leads to defining the M and N fields as follows:

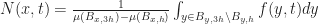
That these equations constitute a generalization of SmoothLife to curved surfaces should be pretty clear (since we barely changed anything at all!). One can recover the original SmoothLife equations by setting 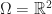
Discrete Riemannian Manifolds
Generalizing SmoothLife to surfaces didn’t change the equations much, but conceptually there is now a whole lot more to unpack. To actually implement this stuff, we need to solve the following three problems:
- First, we need to figure out what metric to use.
- Then, we need some way to compute geodesic balls on a surface.
- Finally, we have to discretize the fields on the surface in some way.
The last part follows along more or less the same sort of reasoning as we applied in the periodic/flat case, (though the details are a bit different). However, items 1 and 2 are new to SmoothLife on curved surfaces and requires some special explanation.
Metric Embeddings
Up to this point, we’ve been deliberately abstract in our dealings with metrics, and haven’t really said much about where they come from. In the most general setting, we can think of a metric as something which is intrinsic to a surface — ie it is part of the very data which describes it. However, in practical applications — especially those arising in computer graphics and engineering — metrics usually come from an embedding. Here’s how it works:
Given a pair of differential manifolds 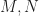
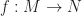




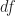
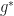
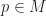

To make this very concrete, let us suppose that our surface is sitting inside 3D Euclidean space. That is we have some smooth map 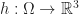
![d(p,q) = \min_{f : [0,1] \to \Omega \\ f(0)=p, f(1)=q} \int_0^1 | \frac{d h(f(t))}{dt} | dt](https://s0.wp.com/latex.php?latex=d%28p%2Cq%29+%3D+%5Cmin_%7Bf+%3A+%5B0%2C1%5D+%5Cto+%5COmega+%5C%5C+f%280%29%3Dp%2C+f%281%29%3Dq%7D+%5Cint_0%5E1+%7C+%5Cfrac%7Bd+h%28f%28t%29%29%7D%7Bdt%7D+%7C+dt&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
In the case of a triangulated mesh, we can let the embedding map just be the ordinary piecewise linear embedding of each triangle into 3-space.
Geodesics on Triangulated Surfaces
Ok, so now that we have a Riemannian metric, the next thing we need to is figure out how to calculate the geodesic distance. As far as I am aware, the first comprehensive solution to this problem was given by Mitchell, Mount and Papadimitrou back in 1987:
J. Mitchell, D. Mount and C. Papadimitrou. (1987) “The Discrete Geodesic Problem” SIAM Journal of Computing
The basic idea behind their algorithm is pretty straightforward, though the details get a little hairy. It basically amounts to a modified version of Dijkstra’s algorithm that computes the single source shortest path to every point along each edge in the mesh. The basic reason this works is that within the interior of each face the actual distance field (for any point source) is always piecewise quadratic. However, there is a catch: the distance along each edge in the mesh might not be quadratic. Instead you may have to subdivide each edge in order to get a correct description of the distance field. Even worse, in that paper Mitchell et al. show that the exact distance field for a mesh with 

Quadratic time complexity is pretty bad — especially for large meshes — but it is really about the best you can hope for if you are trying to solve the problem properly. In fact, a distance field on a piecewise linear triangular surface can have up to 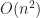
K. Polthier and M. Schmies. (1998) “Straightest Edge Geodesic” Mathematical Visualization
R. Kimmel and J.A. Sethian. (1998) “Computing Geodesic Paths on Manifolds” PNAS
V. Surazhky, T. Surazhky, D. Kirsanov, S. Gortler, H. Hoppe. (2005) “Fast Exact and Approximate Geodesics on Meshes” SIGGRAPH 2005
The first two papers are important in that they describe different ways to look at approximating geodesic distance. Polthier and Schmies give an alternative definition of geodesic distance which is easier to calculate, while Kimmel and Sethian describe a method that approximates the surface itself. Both methods run in 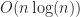

One conclusion that can be drawn from all this is that computing geodesic distance is a hairy problem. Digging around it is easy to get lost in a black hole of different possibilities. Since this is not the main point of this post (and because I wrote most of this code while I was on an airplane without access to the internet), I decided to try just hacking something together and ended up going with the first thing that worked. My approach was to use a modification of the Bellman-Ford algorithm and compute the geodesic distance in two phases. First, I did an iteration of Dijkstra’s algorithm on the edges of the mesh to get an upper bound on the distance, using the Euclidean distance lower bound to trim out far away vertices. Then I iterated unfolding the faces to try to refine the distance field until it converged.
This approach may be novel, but only because it is s obviously terrible compared to other techniques that no one would ever bother to publish it. Nonetheless, in my experiments I found that it gave a passable approximation to the distance field, provided that the mesh had enough subdivisions. The downside though is that the Bellman-Ford algorithm and its variants are quite slow. If I ever have the time, I’d like to revisit this problem some day and try out some better techniques and see how they compare, but that will have to be the subject of another entry. For now, this approach will have to do.
The Finite Element Method
Supposing that we now have some reasonable approximation to geodesic distance (and thus the shape of a geodesic ball) on our mesh, we now need to come up with a way to represent an approximation of the state field on the mesh. Just like in the flat version of SmoothLife, we must use the Galerkin method to discretize the system, but this time there is a major difference. When we were on a flat/periodic domain, we had the possibility of representing the field by a sum of Dirichlet or sinc elements, which turned out to make it really easy to calculate the effective fields M and N using the Fourier transform. However on an arbitrary curved surface (or mesh) we usually don’t have any sort of translational symmetry and so such a representation is not always possible.
Instead, we will have to make do with a somewhat more general, but less efficient, set of basis functions. In engineering applications, one popular choice is to write the field as a sum of splines, (aka smooth compactly supported piecewise polynomial functions). In fact, this idea of using the Galerkin method with splines is so widely used that it even has its own special name: the Finite Element Method (FEM). FEM is basically the default choice for discretizing something when you don’t really know what else to do, since it works for pretty much any sort of topology or boundary condition. The tradeoff is that it can be a lot less efficient than other more specialized bases, and that implementing it is usually much more complicated.
Piecewise Linear Elements
As a first attempt at creating a finite element discretization for SmoothLife, I opted to go with 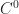
 tent functions. Image (c) Wikipedia 2012. Author: Krishnavedala
tent functions. Image (c) Wikipedia 2012. Author: KrishnavedalaFor a 2D triangulated mesh, the simplest piecewise linear basis functions are the Barycentric coordinates for each face. To explain how this works, let us first describe how we can use these functions to parameterize a single triangle. In a Barycentric coordinate system, a triangle is described as a subset of 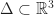
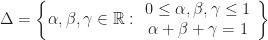
The three vertices of the triangle correspond to the coordinates 
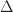


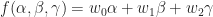
This formula should be pretty familiar if you know a bit about computer graphics. This is the same way a triangle gets mapped into 3D! To get a map from the triangle to any vector space, you can just repeat this type of process for each component separately.
Ok, now that we have some idea of how an embedding works for a single triangle let’s figure out how it goes for a complete mesh. Again we start by describing the parameter space for the mesh. Let us suppose that our mesh is abstractly represented by a collection of 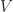
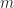
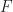

![\alpha_0, \alpha_1, ... \alpha_{n-1} \in [0,1]](https://s0.wp.com/latex.php?latex=%5Calpha_0%2C+%5Calpha_1%2C+...+%5Calpha_%7Bn-1%7D+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
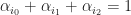
The solution set of all of these constraints cuts out a subset of 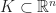
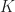
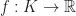
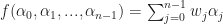
In other words, the basis or `shape’ functions in our discretization are just the Barycentric coordinates 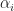

Integration on Meshes
Now that we know our basis functions, we need to say a bit about how we integrate them. To do this, let us suppose that we have a piecewise linear embedding of our mesh which is specified (again in the linear shape functions) by giving a collection of vectors 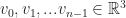
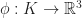
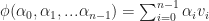
To integrate a scalar function 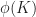
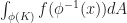
This seems a little scary, but we can simplify it a lot using the fact that 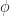
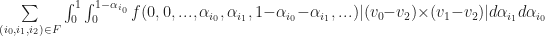
The way you should read that 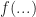
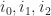
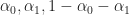
Computing the Effective Fields
Now let’s suppose that we have a state field
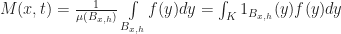
The function 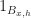
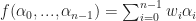
Then we apply the expansion we just described in the previous section:
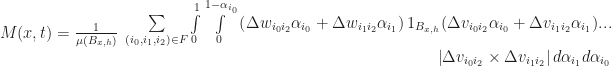
Where:
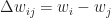
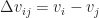
This integral is pretty horrible to compute analytically, but fortunately we don’t have to do that. Instead, we can approximate the true result by using a numerical quadrature rule. The way quadrature rules work is you just sample the integrand and take linear combinations of the results. For cleverly selected weights and sample points, this can even turn out to be exact — though working out exactly the right values is something of a black art. Fortunately, a detailed understanding of this process turns out to be quite unnecessary, since you can just look up the sample points and weights in a book and then plug in the numbers:
J. Burkardt. “Quadrature Rules for Triangles“
It should be obvious that the same trick works for computing 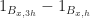
Matrix Formulation and Implementation
To compute the next state of
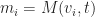
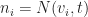
Then we can update
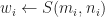
While this would work, it would also be very slow, since computing 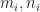
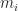
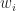
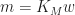
Where 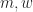
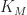
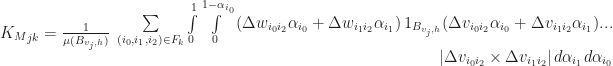
That is, it is a sum over all the faces incident to vertex 

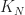
- Use geodesic distance to precompute matrices
- Initialize state vector
- For each time step:
- Set
- Set
- Set
- Set


Demo
If you want to try playing around with this stuff yourself, I made a WebGL demo that should work in Chrome (though I haven’t tested it in Firefox). You can check it out here:
http://mikolalysenko.github.com/MeshLife
Be warned though! It is very slow due to the inefficient calculation of geodesic distances. Of course once it has finished assembling the matrices 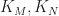
https://github.com/mikolalysenko/RiemannLife
The project is written using node.js and has dependencies on two other libraries I made, namely trimesh.js and meshdata — both of which you can install via npm.
Conclusions
In conclusion, we’ve demonstrated the extended the domain of Rafler’s SmoothLife equations to curved surfaces. While our current implementation is somewhat crude, it does suffice to illustrate that the basic theoretical concepts are sound. In the future, it would be good to investigate alternative methods for computing geodesic distance. At the moment, this is the main bottleneck in the pipeline, and solving it would make further investigation of SmoothLife and related phenomena much easier.
It would also be interesting to attempt a more detailed analysis of the dynamics of SmoothLife. One interesting puzzle would be to try working out the stability of various solitons/gliders in the presence of curvature. It seems that they tend to destabilize and bifurcate near regions of high curvature. This is probably due to the fact that the soliton interacts with itself in these regions. For small curvatures, the trajectory of the solitons are deflected, causing gravitational like effects on their motion.

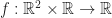 on the plane. Now here is the trick: Instead of thinking of this is an infinite grid of infinitesimal cells, we give the cells a small — but finite! — length. To do this, pick any small positive real number h which will act as the radius of a single cell (ie “the Planck length” for the simulation). Then we define the state of the `effective cell‘ at a point x as the average of the field over a radius h neighborhood around x, (which we call M(x,t) following the conventions in Rafler’s paper):
on the plane. Now here is the trick: Instead of thinking of this is an infinite grid of infinitesimal cells, we give the cells a small — but finite! — length. To do this, pick any small positive real number h which will act as the radius of a single cell (ie “the Planck length” for the simulation). Then we define the state of the `effective cell‘ at a point x as the average of the field over a radius h neighborhood around x, (which we call M(x,t) following the conventions in Rafler’s paper):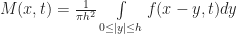
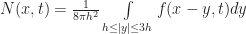

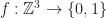 ) and that N, M, give the state of each cell and the number of live cells in the 1-radius
) and that N, M, give the state of each cell and the number of live cells in the 1-radius 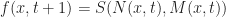
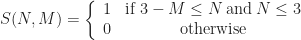
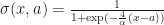
 does if we plot it, taking
does if we plot it, taking 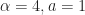 :
:
 from x = -6 to 6. Image (c) Wikipedia 2008. Author Geoff Richards.
from x = -6 to 6. Image (c) Wikipedia 2008. Author Geoff Richards. determines how quickly the sigmoid `steps’ from 0 to 1, while the parameter a shifts the sigmoid. Using a sigmoid, we can represent 0/1, alive/dead state of a cell in the effective field by thresholding:
determines how quickly the sigmoid `steps’ from 0 to 1, while the parameter a shifts the sigmoid. Using a sigmoid, we can represent 0/1, alive/dead state of a cell in the effective field by thresholding: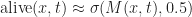
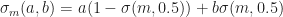
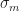 selects between a and b depending on whether the cell is dead or alive respectively. The other thing we will need is a way to smoothly threshold an interval. Fortunately, we can also do this using
selects between a and b depending on whether the cell is dead or alive respectively. The other thing we will need is a way to smoothly threshold an interval. Fortunately, we can also do this using 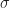 . For example, we could define:
. For example, we could define:

 for n=0 to 1
for n=0 to 1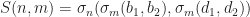
![[b_1, d_1], [b_2, d_2]](https://s0.wp.com/latex.php?latex=%5Bb_1%2C+d_1%5D%2C+%5Bb_2%2C+d_2%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002) are a pair of intervals which are selected based on user specified parameters. Based on the game of life, a reasonable set of choices should be
are a pair of intervals which are selected based on user specified parameters. Based on the game of life, a reasonable set of choices should be 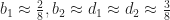 , which if plotted gives a chart that looks something like this:
, which if plotted gives a chart that looks something like this:
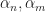 for their appearance in
for their appearance in 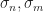 respectively. Along with the bounds for the the life/death intervals
respectively. Along with the bounds for the the life/death intervals 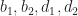 , there are 6 total parameters to choose from in building a cellular automaton for SmoothLife.
, there are 6 total parameters to choose from in building a cellular automaton for SmoothLife.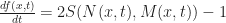
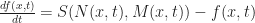
 (which I will deliberately leave unspecified for now):
(which I will deliberately leave unspecified for now):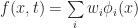
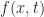 . For example, we could represent f as a polynomial series expansion, in which case
. For example, we could represent f as a polynomial series expansion, in which case 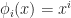 and the weights would just be the coefficients,
and the weights would just be the coefficients, 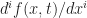 . But there is no reason to stop at polynomials, we could approximate f by whatever functions we find convenient (and later on we’ll discuss a few reasonable choices.) What does this buy us? Well if we use a finite number of basis elements,
. But there is no reason to stop at polynomials, we could approximate f by whatever functions we find convenient (and later on we’ll discuss a few reasonable choices.) What does this buy us? Well if we use a finite number of basis elements, 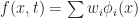 at time t, and supposing that at time t+1 we have
at time t, and supposing that at time t+1 we have 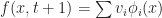 , all we need to do is solve for the coefficients
, all we need to do is solve for the coefficients  . This could be done (hypothetically) by just plugging in f(x,t), f(x,t+1) into both sides of Rafler’s SmoothLife update equation:
. This could be done (hypothetically) by just plugging in f(x,t), f(x,t+1) into both sides of Rafler’s SmoothLife update equation: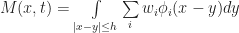
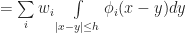
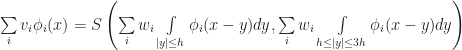
 error in some suitable metric. For example, we could try to solve the following the following optimization problem instead:
error in some suitable metric. For example, we could try to solve the following the following optimization problem instead: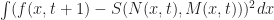
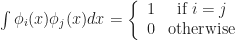

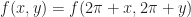
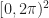 . This square is compact and so we have at least some hope of being able to approximate a periodic f by some finite number of functions covering this square.
. This square is compact and so we have at least some hope of being able to approximate a periodic f by some finite number of functions covering this square.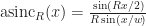
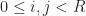 with:
with: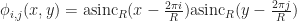 .
.
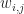 are just the values of the function at the grid points:
are just the values of the function at the grid points: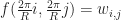
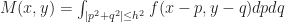
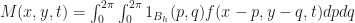
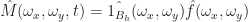
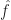 is a finite sum. Therefore:
is a finite sum. Therefore: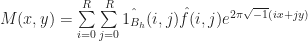
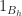 can be computed in closed form using Bessel functions. This means that:
can be computed in closed form using Bessel functions. This means that: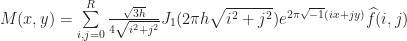
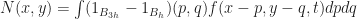
 be the new weights for f at time t+1. Then to do a discrete time step we just set:
be the new weights for f at time t+1. Then to do a discrete time step we just set: