Last time, we showed how one can use symmetric tensors to conveniently represent homogeneous polynomials and Taylor series. Today, I am going to talk about how to actually implement a generic homogeneous polynomial/symmetric tensor class in C++. The goal of this implementation (for the moment) is not efficiency, but rather generality and correctness. If there is enough interest we can investigate some optimizations perhaps in future posts.
How to deal with polynomials?
There are quite a few ways to represent polynomials. For the moment, we aren’t going to assume any type of specialized sparse structure and will instead simply suppose that our polynomials are drawn at random from some uniform distribution on their coefficients. In some situations, for example in the solution of various differential equations, this is not too far from the truth, and while there may be situations where this assumption is too pessimistic, there are at least equally many situations where it is a good approximation of reality.
In 1D, the most direct method to represent a dense, inhomogeneous polynomial is to just store a big array of coefficients, where the 
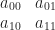
Which we could then expand out to give a polynomial like:

Though it is a bit simplistic, working in this format does have a few advantages. For example:
- Evaluating a polynomial is easy. Just compute the vectors
and the then plug them into the coefficient tensor using ordinary Einstein summation.
- Multiplying can also be pretty fast. Observe that coefficient matrix of the product of two polynomial matrices is just the convolution of their two matrices. Using fast convolution algorithms (for example an FFT based method would work), this can be computed with only a mere log factor overhead!
The amount of storage for representing a polynomial on 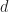

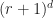
- It doesn’t capture all the terms above degree r properly. For example, if you take the term
from the above example, it is actually second order, and so is the polynomial that it represents. However, we are missing the extra terms for
.
- Related to the previous point, it is not closed under linear coordinate transformations. If you were to say do a rotation in
, that
, and thus we would need to resize the matrix to keep up with the extra stuff.
- If you only care about storing terms with degree at most
.
- And if you want to deal with terms that are exactly degree d, then it is even worse with an overhead of
.
The underlying cause for each of these problems is similar, and ultimately stems from the fact that the function 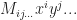
Quick Review
Recall that a homogeneous polynomial on d variables, 

We also showed that this could be written equivalently using tensor notation:
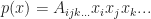
Which allows us to reinterpret p as a “r-multilinear function” on x. We say that a function 


While it may seem a bit restrictive to work in homogeneous polynomials only, in practice it doesn’t make much difference. Here is a simple trick that ought to be familiar to anyone in computer graphics who knows a bit about projective matrices. Let us consider the following 1D example (which trivially generalizes): given a polynomial in one variable,
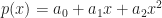
Let us create a new variable 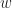
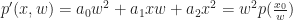
Now we observe that:
is a homogeneous polynomial of degree 2.
- If we pick
, then
.
And so we have faithfully converted our inhomogeneous degree 2 polynomial in one variable into a new homogeneous degree 2 polynomial in two variables!
In general, converting from an inhomogeneous polynomial to a homogeneous polynomial is a simple matter of adding an extra variable. The fully generalized version works like this: Suppose that we have a polynomial 

And again, 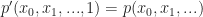
Indexing, iteration and combinatorics
So with that stuff above all out of the way, we shall now settle on an implementation: we’re going to use symmetric tensors to represent homogeneous polynomials. Let us start off by listing a few basic properties about symmetric tensors:
- A tensor
is called symmetric if for all permutations of an index,
and so on,
.
- As a result, all vectors (aka a rank-1 tensors) are trivially symmetric.
- Similarly, a matrix is symmetric if and only if
.
- A rank 3 tensor is symmetric if
(and so on).
- Consequently is the dimension of each of the indices in a symmetric tensor must be equal, and so we shall sometimes refer to this quantity as the “dimension of the tensor”, or when we need to be more specific we shall call it the index dimension.
- The dimension of the space of all symmetric tensors with rank r and (index) dimension d is
.
And so the first problem that we must solve is to figure out how to pack the coordinates of a general rank r, dimension d symmetric tensor into an array of size
By definition, the entries of a symmetric tensor are invariant under index permutation. This leads to two distinct ways to index into a symmetric rank r dimension d tensor:
- Tensor style indexing – This is the ordinary way that we write the index for a generic tensor using subscripts. Entries of the tensor are parameterized by a length r vector of integers,
where
for all
.
- Polynomial style (degree) indexing – This is the style of indexing is unique to symmetric tensors and comes from their close association with polynomials. Here, we take the index to be the degree of one of the monomial terms in the corresponding homogeneous polynomial These indices are enumerated by length d vectors of integers,
where
for all k, and
.
We can convert between these two types of indexes up to a point. Converting from tensor indexing to degree indexing is straightforward, where we just pick
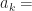
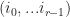
Going the other way is a bit harder, since there are multiple tensor indices which map to the same degree index. To resolve the ambiguity, we can simply take the lexicographically first item. This same idea also turns out to be useful for enumerating the entries within our tensor. For example, suppose that we wanted to enumerate the components of a rank 3, degree 4 tensor. Then, we could use the following ordering,
Pos. Tensor Degree ------------------------- 0 (0,0,0) (3,0,0,0) 1 (1,0,0) (2,1,0,0) 2 (2,0,0) (2,0,1,0) 3 (3,0,0) (2,0,0,1) 4 (1,1,0) (1,2,0,0) 5 (2,1,0) (1,1,1,0) 6 (3,1,0) (1,1,0,1) 7 (2,2,0) (1,0,2,0) 8 (3,2,0) (1,0,1,1) 9 (3,3,0) (1,0,0,2) 10 (1,1,1) (0,3,0,0) 11 (2,1,1) (0,2,1,0) 12 (3,1,1) (0,2,0,1) 13 (2,2,1) (0,1,2,0) 14 (3,2,1) (0,1,1,1) 15 (3,3,1) (0,1,0,2) 16 (2,2,2) (0,0,3,0) 17 (3,2,2) (0,0,2,1) 18 (3,3,2) (0,0,1,2) 19 (3,3,3) (0,0,0,3)
Here, the left hand column represents the order in which the entries of the tensor were visited, while the middle column is the set of unique tensor indices listed lexicographically. The right hand side is the corresponding degree index, which is remarkably in colexicographic order! This suggests other interesting patterns as well, such as the following little theorem:
Proposition: Colexicographically sort all the degree indices in a rank r, d-dimensional symmetric tensor. Then the position of the degree index,
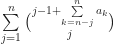
(That is supposed to be a binomial coefficient, but the parenthesis seem to be a bit messed up in wordpress.) I will leave this proof as an exercise to the reader, but offer the hint that it can be proven directly by induction. It is also interesting to note that the formula for the position does not depend on either the rank of the tensor or the first coefficient.
Putting it all together
Now let us try to work out a method for iterating the tensor index incrementally. A simple strategy is to use a greedy method: We just scan over the index until we find a component that can be incremented, then scan backwards and reset all the previous indices. In psuedo-C++, the code looks something like this:
bool next() {
for(int i=0; i<rank; ++i) {
if(tensor_index[i] < dimension - 1) {
++tensor_index[i];
for(int j=i-1; j>=0; --j) {
tensor_index[j] = tensor_index[i];
}
return true;
}
}
return false;
}
The tensor_index array contains rank elements, and is initialized to all 0’s before this code is called. Each call to next() advances tensor_index one position.
Superficially, there are some similarities between this algorithm and the method for incrementing a binary counter. As a result, I propose the following conjecture (which I have not investigated carefully enough to say is true confidently):
Conjecture: Amortized over course of a full traversal, the cost of next is constant.
Using all this stuff, I’ve put together a little C++ class which iterates over the coordinates of a symmetric tensor. I’ve also uploaded it to github, where you can go download and play around with it (though it isn’t much). I hope to keep up this trend with future updates. For those who are curious, here is the URL:
https://github.com/mikolalysenko/0fpsBlog
Next time
In the next episode, I am going to continue on this journey and build an actual symmetric tensor class with a few useful operations in it. More speculatively, we shall then move on to rational mappings, algebraic surfaces, transfinite interpolation and deformable objects!
