My god… I’ve now written three blog posts about Minecraft. If you are at all like me, you may be getting just a bit tired of all those cubes. To avoid fatigue, I think now is a good time to change things up. So today let’s talk about something cool and different — like how to deal with smooth blobby shapes:

- A rendering of Goursat’s surface.
Blobby Objects
But before we get too far ahead of ourselves, we need to say what exactly a blobby object is. The term `blobby object’ is one of Jim Blinn’s many contributions to computer graphics, though some of the basic ideas go back much further. In fact mathematicians have known about blobs for centuries (before they even had calculus!) Conceptually, the basic idea of a blobby object is quite simple, though it can be a bit tricky to formalize it properly.
The theoretical basis for blobby object modeling is the concept of an implicit solid. The idea is that we can represent a solid object by a contour of a smooth function. I found the following beautiful picture from wikipedia that illustrates the concept:

- Public domain illustration of a 2D implicit set. (c) Wikimedia, created by Oleg Alexandrov.

Now we want to get a solid (that is a closed regular set) — not just any old sublevel set. Fortunately, the definition is pretty simple once you’ve seen it and get used to it. Given any continuous function, 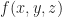
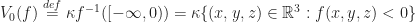
(Here I’m using the symbol 
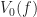
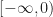
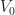
![Z_0(f) \stackrel{def}{=} f^{-1}( [-\infty, 0] ) = \{ (x,y,z) \in \mathbb{R}^3 : f(x,y,z) \leq 0 \}](https://s0.wp.com/latex.php?latex=Z_0%28f%29+%5Cstackrel%7Bdef%7D%7B%3D%7D+f%5E%7B-1%7D%28+%5B-%5Cinfty%2C+0%5D+%29+%3D+%5C%7B+%28x%2Cy%2Cz%29+%5Cin+%5Cmathbb%7BR%7D%5E3+%3A+f%28x%2Cy%2Cz%29+%5Cleq+0+%5C%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Spiritually, this is the right idea but technically it doesn’t quite work. It is true that in many situations, these two definitions give similar results. For example, let’s consider the 1D function 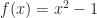
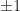

In this case, both 
![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
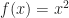

Then
- First,
is not necessarily a solid. This means that it is not always uniquely determined by its boundary, and that certain mass properties (like volume, inertia, momentum, etc.) may fail to be well defined. On the other hand,
- Closely related to the first point, it is very difficult to define regularized Boolean operation on the latter representation, while it is possible to perform CSG operations regularized sublevels using Rvachev functions. (Maybe I will say more about this at some point in the future.)
- Finally, it is not even practically possible to numerically compute
To boil all this down to a pithy remark:
The reason we prefer
My personal reason for preferring
Isosurface Extraction
Now that we’ve hopefully got a decent mental picture of what we want to find, let’s try to figure out how to compute something with it. In particular, we are most interested in finding the boundary of the implicit set. An obvious application would be to draw it, but knowing the boundary can be equally useful for other tasks as well; like computing mass properties for example.
In light of our previous definition, the boundary of our implicit solid is going to be the set of all 0-crossings of f. One perspective is that computing the boundary is like a higher dimensional generalization of root finding. Thinking metaphorically for a moment and confusing 0-values with 0-crossing, it is like saying that instead of trying to find solutions for:
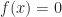
We are now looking for all solutions to the more general problem:
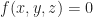
In the first case, we get some points as an output, while in the second case the solution set will look like some surface.
Implicit Function Theorem
It turns out that at least when f is smooth, we can convert implicit sets locally into parametric surfaces. This is the content of the implicit function theorem. Finding such a parametric surface is as good as solving the equation. For example, say we had a paraboloid given by:
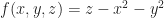
Then we could parameterize the 0-set by the surface:
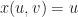
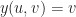

When you have a parametric solution, life is good. Unfortunately, for more complicated equations (like Perlin noise for example), finding a parametric solution is generally intractable. It also doesn’t work so well if your implicit function happens to come from some type of sampled geometry, such as a distance field or a point cloud. As a result, exact parametric solutions are generally too much to hope for.
Ray Tracing
A more general solution to the problem of isosurface extraction is ray tracing, which is basically a form of dimensionality reduction. The idea is that instead of trying to find the whole isosurface, we instead just look to query it locally. What we do is define some ray (or more generally any curve) ![\varphi : [0,1] \to \mathbb{R}^3](https://s0.wp.com/latex.php?latex=%5Cvarphi+%3A+%5B0%2C1%5D+%5Cto+%5Cmathbb%7BR%7D%5E3&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

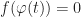
This is now a standard 1D root-finding problem, and we could solve it using either symbolically or using techniques from calculus, like bisection or Newton’s method. For example, in path tracing, one usually picks a collection of rays corresponding to the path light would take bouncing through the scene. Then all we need to do is check where these individual rays meet the surface, rather than compute the entire thing all at once (though it can still become very expensive).
Meshing
For most interesting functions, it is neither possible to find a parametric description, nor is ray tracing really fast enough. Instead, it is often more practical to look at finding some polygonal approximation of the implicit surface instead. Broadly speaking, this process has two parts:
- First, we approximate
by sampling
- Then, from this sampled version of
.
Of course there are many details hidden within this highly abstract description. I wrote up a fairly lengthy exposition, but ended up more than tripling the length of this post! So, I think now is a good time to take a break.
Next Time
Next time we’ll talk about how to put all this stuff into practice. The focus is going to be on meshing, since this is probably the most important thing to deal with in practice. As a sneak preview of things to come, here is a demo that I put together. I promise all (well ok at least something) will be explained in the coming post!

One thought on “Smooth Voxel Terrain (Part 1)”