Collision, or intersection, detection is an important geometric operation with a large number of applications in graphics, CAD and virtual reality including: map overlay operations, constructive solid geometry, physics simulation, and label placement. It is common to make a distinction between two types of collision detection:
- Narrow phase: Test if 2 objects intersect
- Broad phase: Find all pairs of intersections in a set of n objects
In this series, I want to focus on the latter (broad phase), though first I want to spend a bit of time surveying the bigger picture and explaining the significance of the problem and some various approaches.
Narrow phase
The approach to narrow phase collision detection that one adopts depends on the types of shapes involved:
Constant complexity shapes
While it is true that for simple shapes (like triangles, boxes or spheres) pairwise intersection detection is a constant time operation, because it is frequently used in realtime applications (like VR, robotics or games) an enormous amount of work has been spent on optimizing. The book “Realtime Collision Detection” by Christer Ericson has a large collection of carefully written subroutines for intersection tests between various shapes which exploit SIMD arithmetic,
C. Ericson, (2004) “Realtime Collision Detection“
There is also a table of various collision detection predicates collected from different sources at realtimerendering.com.
Convex polytopes
For more complicated shapes (that is shapes with a description length longer than 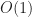
- V-Polytope: As the set of all convex combinations of a finite set of points and possibly infinite direction vectors (aka 1D cones)
- H-Polytope: As the intersection of a finite set of closed linear half spaces.
These two representations are equivalent in their descriptive power (though proving this is a bit tricky). The process of converting a V-polytope into an H-polytope is called taking the “convex hull” of the points, and the dual algorithm of converting an H-polytope into a V-polytope is called “vertex enumeration.”
The problem of testing if two convex polytopes intersect is a special case of linear programming feasibility. This is pretty easy to see for H-polytopes; suppose that:
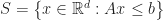
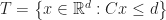
Where,
is a n-by-d matrix
is a n-dimensional vector
is a m-by-d matrix
is a m-dimensional vector
Then the region 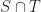
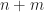
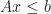
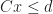
If this system has a solution (that is it is feasible), then there is a common point 
Linear programs are a special case of LP-type problems, and for low dimensions can be solved linear time in the number of half spaces or variables. (For those curious about the details, here are some lectures). For example, using Seidel’s algorithm testing the feasibility of the above system takes 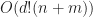

Preprocessing
If we are willing to preprocess the polytopes, it is possible to do exponentially better than 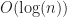
The 3D case is a bit trickier, but it can be solved in 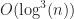
B. Chazelle, D. Dobkin. (1988) “Intersection of convex objects in two and three dimensions” Journal of the ACM
For interactive applications like physics simulations, another important technique is to reuse previous closest points in calculating distances (similar to using a warm restart in the simplex method for linear programming). This ideas were first applied to collision detection in the now famous Lin-Canny method:
M. Lin, J. Canny, (1991) “A fast algorithm for incremental distance calculation” ICRA
For “temporally coherent” collision tests (that is repeatedly solved problems where the shapes involved do not change much) the complexity of this method is practically constant. However, because it relies on a good initial guess, the performance of the Lin-Canny method can be somewhat poor if the objects move rapidly. More recent techniques like H-walk improve on this idea by combining it with fast data structures for linear programming queries, such as the Dobkin-Kirkpatrick hierarchy to get more robust performance:
L. Guibas, D. Hsu, L. Zhang. (1999) “H-Walk: Hierarchical distance computation for moving bodies” SoCG
Algebraic and semialgebraic sets
Outside of convex polytopes, the situation for resolving narrow phase collisions efficiently and exactly becomes pretty hopeless. For algebraic sets like NURBS or subdivision surfaces, the fastest known methods all reduce to some form of approximate root finding (usually via bisection or Newton’s method). Exact techniques like Grobner basis are typically impractical or prohibitively expensive. In constructive solid geometry working with semialgebraic sets, it is even worse where one must often resort to general nonlinear optimization, or in the most extreme cases fully symbolic Tarski-Seidenberg quantifier elimination (like the cylindrical algebraic decomposition).
Measure theoretic methods
I guess I can say a few words about some of my own small contributions here. An alternative to computing the distance between two shapes for testing separation is to compute the volume of their intersection, 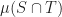
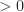
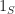

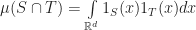
This integral is essentially a dot product. If we perform an expansion of 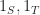
M. Lysenko, (2013) “Fourier Collision Detection” International Journal of Robotics Research
The advantage to this type of approach to collision detection is that it can support any sort of geometry, no matter how complicated. This is because the cost of the testing intersections scales with the accuracy of the collision test in a predictable, well-defined way. The disadvantage though is that at high accuracies it is slower than other exact techniques. Whether it is worthwhile or not depends on the desired accuracy, the types of shapes involved and if additional information like a separating axis is needed and so on.
Broad phase
Given a fast narrow phase collision test, we can solve the broad phase collision detection problem for 
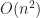
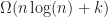
Special cases
If we are only allowed to use pairwise intersection tests and know no other property of the shapes, then it is impossible to compute all pairwise intersections any faster than 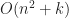
Line segments
For line segments in the plane, it is possible to report all intersections in 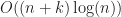
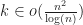
Uniformly sized and distributed balls
It is also possible to find all intersections in a collection of balls with constant radii in optimal 
Axis aligned boxes
Finally, it is possible to detect all intersections in a collection of axis aligned boxes in 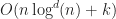
General objects and bounding volumes
For general objects, no algorithms with running time substantially faster than 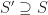
In practice, the most common choice for a bounding volume is either a box or a sphere. The reason for this is that boxes and spheres support efficient broad phase intersection tests, and so they are relatively cheap.
Spheres tend to be more useful if all of the shapes are more or less the same size, but computing tight bounding spheres is slightly more expensive. For example, if the objects being intersected consist of uniformly subdivided triangle meshes, then spheres can be a good choice of bounding volume. However, spheres do have some weakness. Because testing sphere intersection requires multiplication, it is harder to do it exactly than it is for boxes. Additionally, for spheres of highly variable sizes it is harder to detect intersections efficiently.
Computing intersections in boxes on the other hand tends to be much cheaper, and it is simpler to exactly detect if a pair of boxes intersect. Also for many shapes boxes tend to give better approximations than spheres, since they can have skewed aspect ratios. Finally, broad phase box intersection has theoretically more robust performance than sphere intersection for highly variable box sizes. Perhaps based on these observations, it seems that most modern high performance physics engines and intersection codes have converged on axis-aligned boxes as the preferred primitive for broad phase collision detection. (See for example, Bullet, Box2D)
Bipartite vs complete
It is sometimes useful to separate objects for collision detection into different groups. For example if we are intersecting water-tight meshes, it is useless to test for self intersections. Or as another example, in a shooter game we only need to test the player’s bullets against all enemies. These are both examples of bipartite collision detection. In bipartite collision detection, we have two groups of objects (conventionally colored red and blue), and the goal is to report all pairs of red and blue objects which intersect.
Range searching and more references
There is a large body of literature on intersection detection and the related problems of range searching. Agarwal and Erickson give an excellent survey of these results in the following paper,
P.K. Agarwal, J. Erickson. (1997) “Geometric range searching and its relatives“
Next time
In the next article, we will look at broad phase collision detection in more depth, focusing on boxes as a basic primitive.

I really wish there were more blogs like yours that focus more on maths/algorithms instead of general debate. I am currently working on (yet another) voxel engine, primarily as a means to learn about game engine design and algorithms. Almost all of your articles are useful, and I can’t wait to see part 2 of this one!
Btw programming is entirely a spare time hobby for me. I’m actually studying Electronic Engineering at university.
In the future there will be a “knowledge transfer” where you just chill and download peoples knowledge at the behest of your connection. In that future, expect the doorbell to ring my friend.