Previously in this series we covered the basics of collision detection and discussed some different approaches to finding intersections in sets of boxes:
Today, we’ll see how well this theory squares with reality and put as many algorithms as we can find to the test. For those who want to follow along with some code, here is a link to the accompanying GitHub repo for this article:
The Great JavaScript Box Intersection Benchmark
Finding modules
To get a survey of the different ways people solve this problem in practice, I searched GitHub, Google and npm, and also took several polls via IRC and twitter. I hope that I managed to cover most of the popular libraries, but if there is anything here that I missed, please leave a comment and let me know.
While it is not an objective measurement, I have also tried to document my subjective experiences working each library in this benchmark. In terms of effort, some libraries took far less time to install and configure than others. I also took notes on libraries which I considered, but rejected for various reasons. These generally could be lumped into 3 categories:
- Broken: The library did not report correct results.
- Too much work: Setting up the library took too long. I was not as rigorous with enforcing a tight bound here, as I tended to give more generous effort to libraries which were popular or well documented. Libraries with 0 stars and no README I generally skipped over.
- Irrelevant: While the library may have at first looked like it was relevant, closer inspection revealed that it did not actually solve the problem of box intersection. This usually happened because the library had a suspicious name, or because it was some framework whose domain appeared to include this problem.
A word on JavaScript
For the purpose of this benchmark, I limited myself to consider only JavaScript libraries. One major benefit of JavaScript is that it is easier to install and configure JavaScript libraries, which greatly simplifies the task of comparing a large number of systems. Also, due to the ubiquity of JavaScript, it is easy for anyone to replicate these results or rerun these benchmarks on their own machine. The disadvantage though is that there are not as many mature geometry processing libraries for JavaScript as there are for older languages like C++ or Java. Still, JS is popular enough that I had no trouble finding plenty of things to test although the quality of these modules turned out to be wildly varying.
Implementations surveyed
Brute force
As a control I implemented a simple brute force 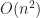
Bounding volume hierarchy modules
I found many modules implementing bounding volume hierarchies, usually in the form of R-trees. Here is a short summary of the ones which I tested:
- rbush: This is one of the fastest libraries for box intersection detection. It also has a very simple API, though it did take a bit of time tuning the branching factor to get best performance on my machine. I highly recommend checking this one out!
- rtree: An older rtree module, which appears to have largely been replaced by rbush. It has more features, is more complicated, and runs a bit slower. Still pretty easy to use though.
- jsts-strtree: The jsts library is a JavaScript port of the Java Topology Suite. Many of the core implementations are solid, but the interfaces are not efficient. For example, they use the visitor pattern instead of just passing a closure to enumerate objects which requires lots of extra boilerplate. Overall found it clumsy to use, but reasonably performant.
- lazykdtree: I included this library because it was relatively easy to set up, even though it ended up being very slow. Also notable for working in any dimension.
Quad trees
Because of their popularity, I decided to make a special section for quad trees. By a survey of modules on npm/GitHub, I would estimate that quad trees are one of the most commonly implemented data structures in JavaScript. However it is not clear to me how much of this effort is serious. After much searching, I was only able to find a small handful of libraries that correctly implemented quad trees based rectangle stabbing:
- simple-quadtree: Simple interface, but sluggish performance.
- jsts-quadtree: Similar problems as jsts-strtree. Unlike strtree, also requires you to filter out the boxes by further pruning them against your query window. I do not know why it does this, but at least the behavior is well documented.
Beyond this, there many other libraries which I investigated and rejected for various reasons. Here is a (non-exhaustive) list of some libraries that didn’t make the cut:
- Google’s Closure Library: This library implements something called “quadtree”, but it doesn’t support any queries other than set membership. I am still not sure what the point of this data structure is.
- quadtree2: Only supports ball queries, not boxes
- Mike Chamber’s QuadTree: Returns incorrect results
- quadtree-javascript: Returns incorrect results
- node-trees: Returns incorrect results
- giant-quadtree: Returns incorrect results
- generic-quadtree: Only implements point-in-rectangle queries, not rectangle-rectangle (stabbing) queries.
- quadtree: I’m don’t know what this module does, but it is definitely not a quad tree.
Physics engines
Unfortunately, many of the most mature and robust collision detection codes for JavaScript are not available as independent modules. Instead, they come bundled as part of some larger “physics framework” which implements multiple algorithms and a number of other features (like a scene graph, constraint solver, integrator, etc.). This makes it difficult to extract just the collision detection component and apply it to other problems. Still, in the interest of being comprehensive, I was able to get a couple of these engines working within the benchmark:
- p2.js: A popular 2D physics engine written from the ground up in JavaScript. Supports brute force, sweep and prune and grid based collision detection. If you are looking for a good 2D physics engine, check this one out!
- Box2D: Probably the de-facto 2D physics engine, has been extremely influential in realtime physics and game development. Unfortunately, the quality of the JS translations are much lower than the original C version. Supports sweep-and-prune and brute force for broad phase collision detection.
- oimo.js: This 3D physics engine is very popular in the THREE.js community. It implements brute force, sweep and prune and bounding volume hierarchies for collision detection. Its API is also very large and makes heavy use of object-oriented programming, which comes with some performance tradeoffs. However oimo does deserve credit for being one of the few libraries to tackle 3D collision detection in JavaScript.
I also considered the following physics engines, but ended up rejecting them for various reasons:
- cannon.js: To its credit, cannon.js has a very clear API and well documented code. It is also by the same author as p2.js, so it is probably good. However, it uses spheres for broad phase collision detection, not boxes, and so it is not eligible for this test.
- GoblinPhysics: Still at very early stages. Right now only supports brute force collision detection, but it seems to be progressing quickly. Probably good to keep an eye on this one.
- PhysicsJS: I found this framework incredibly difficult to deal with. I wasted 2 days trying to get it to work before eventually giving up. The scant API documentation was inconsistent and incomplete. Also, it did not want to play nice in node.js or with any other library in the browser, hooking event handlers into all nooks and crannies of the DOM, effectively making it impossible to run as a standalone program for benchmarking purposes. Working with PhysicsJS made me upset.
- Matter.js: After the fight with PhysicsJS, I didn’t have much patience for dealing with large broken libraries. Matter.js seems to have many of the same problems, again trying to patch a bunch of weird stuff onto the window/DOM on load, though at least the documentation is better. I spent about an hour with it before giving up.
- ammo.js/physijs: This is an emscripten generated port of the popular bullet library, however due to the translation process the API is quite mangled. I couldn’t figure out how to access any of the collision detection methods or make it work in node, so I decided to pass on it.
Range-trees
Finally, I tried to find an implementation of segment tree based intersection for JavaScript, but searching turned up nothing. As far as I know, the only widely used implementation of these techniques is contained in CGAL, which comes with some licensing restrictions and also only works in C++. As a result, I decided to implement of Edelsbrunner & Zomorodian’s algorithm for streaming segment trees myself. You can find the implementation here:
box-intersect: Fast and robust d-dimensional box intersection
The code is available under a liberal MIT license and easily installable via npm. It should work in any modern CommonJS environment including browserify, iojs and node.js.
Testing procedure
In each of these experiments, a set of 
Because algorithms for collision detection are output sensitive, care was taken to ensure that the total number of intersections in each distribution is at most 
A limitation of this protocol is that it favors batched algorithms (as would be typically required in CAD applications), and so it may unfairly penalize iterative algorithms like those used in many physics engines. To assess the performance of algorithms in the context of dynamic boxes more work would be needed.
Results
Here is a summary of the results from this benchmark. For a more in depth analysis of the data, please see the associated GitHub repo. All figures in this work were made with plot.ly, click on any of the images to get an interactive version.
Uniform distribution
I began this study by testing each algorithm against the uniform distribution. To ensure that the number of intersections is at most 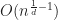
![[0,1]^d](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5Ed&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

To save time, I split the trials into phases ordered by number of boxes; algorithms which performed took too long on smaller instances were not tested on larger problem sizes. One of the first and most shocking results was a test instance I ran with just 500 boxes:

Here two libraries stand out for their incredibly bad performance: Box2D and lazykdtree. I am not sure why this situation is so bad, since I believe the C version of Box2D does not have these problems (though I need to verify this). Scaling out to 1500 boxes without these two libraries gives the following results:

The next two worst performing libraries were simple-quadtree and rtree. simple-quadtree appears to have worse than quadratic growth, suggesting fundamental algorithmic flaws. rtree’s growth is closer to 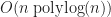

At this point, the performance of brute force begins to grow too large, and so it was omitted from the large brute force tests.
Because p2’s sweep method uses an insertion sort, it takes
Both of jsts’ data structures continue to trend at about 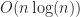
10000 boxes appears to be the cut off for real time simulation (or 60fps) at least on my machine. Beyond, this point, even the fastest collision detection algorithm (in this case box-intersect) takes at least 16ms. It is unlikely that any purely JavaScript collision detection library would be able to handle significantly more boxes than this, barring substantial improvements in either CPU hardware or VM technology.
One surprise is that within this regime, box-intersect is consistently 25-50% faster than p2-grid, even though one would expect the 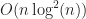

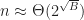

As expected, somewhere between 10000 and 20000 boxes, p2-grid finally surpasses box-intersect. This is expected as grids realize
The complexity of rbush on this distribution is more subtle. For the bulk insertion method, rbush uses the “overlap minimizing tree” (OMT) heuristic of Lee and Lee,
T. Lee, S. Lee. (2003) “OMT: Overlap minimizing top-down bulk loading algorithm for R-Trees” CAiSE
The OMT heuristic partitions the space into an adaptive 
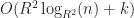

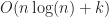

Sphere
Of course realistic data is hardly ever uniformly distributed. In CAD applications, most boxes tend to be concentrated in a lower dimensional sub-manifold, typically on the boundary of some region. As an example of this case, we consider boxes which are distributed over the surface of a sphere (again with the side lengths scaled to ensure that the expected number of collisions remains at most

To streamline these benchmarks, I excluded some of the worst performing libraries from the comparison. Starting with a small case, here are the results:

Again, brute force and p2’s sweep reach similar
More significantly, p2-grid did not perform as well as in the uniform case, running an order of magnitude slower. This is as theory would predict, so no real surprises. Continuing the trend out to 50k boxes gives the following results,

Both p2-grid and jsts-quadtree diverge towards
Both rbush and jsts-strtree show similar growth rates, as they implement nearly identical algorithms, however the constant factors in rbush are much better. The large gap in their performance can probably be explained by the fact that jsts uses Java style object oriented programming which does not translate to JavaScript well.
One way to understand the OMT heuristic in rbush, is that it is something like a grid, only hedged against sparse cases (like this circle). In the case of a uniform distribution, it is not quite as fast as a grid, suffering a 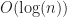
Again box-intersect delivers consistent 
High aspect ratio
Finally, we come to the challenging case of high aspect ratio boxes. Here we generate boxes which are uniformly distributed in 
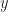

High aspect ratio boxes absolutely destroy the performance of grids and quad trees, causing exponential divergence in complexity based on the aspect ratio. Here are some results,

Even for very small 
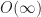
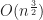

In this case rbush-bulk takes more than 40x slower and rbush-bulk more than 70x. Unlike in the case of grids however, these numbers are only realized by scaling in the number of boxes and so they cannot be made arbitrarily large. However, it does illustrate that for certain inputs rbush will fail catastrophically. box-intersect again continues to grow very slowly.
3D
The only libraries which I found that implemented 3D box intersection detection were lazykdtree and oimo.js. As it is very popular, I decided to test out oimo’s implementation on a few small problem sizes. Results like the following are typical:

Conclusions
For large, uniform distributions of boxes, grids are still the best. For everything else, use segment trees.
- Brute force is a good idea up to maybe 500 boxes or so.
- Grids succeed spectacularly for large, uniform distributions, but fail catastrophically for anything more structured.
- Quad trees (at least when properly implemented) realize similar performance as grids. While not as fast for uniform data, they are slightly hedged against boxes of wildly variable size.
- RTrees with a tuned heuristic can give good performance in many practical cases, but due to theoretical limitations (see the previous post), they will always fail catastrophically in at least some cases, typically when dealing with boxes having a high aspect ratio.
- Zomorodian & Edelsbrunner’s streaming segment tree algorithm gives robust worst case
performance no matter what type of input you throw at it. It is even faster than grids for uniform distributions at small problem sizes(<10k) due to superior cache performance.
Overall, streaming segment trees are probably the safest option to select as they are fastest in almost every case. The one exception is if you have a large number of uniformly sized boxes, in which case you might consider using a grid.

Thank you for such a wonderful, detailed article! Glad my rbush coped well. 🙂
I’d love to see part 4 with insertion/removal time comparisons! This was my main focus when developing rbush since insertion rather than search was a bottleneck in all use cases I use rbush in.
Thanks for the comment and for making such a great library!
A dynamic test would be pretty interesting, but I don’t have enough energy to do it right now. Still I would love to see someone take on this problem and am curious what the results would be.
Could you flip the charts to show collisions per second? The best libraries are all squashed down at the bottom and it’s hard to see which one is really better. OTOH it wouldn’t be a problem if useless libraries were asymptotically approaching 0.
🙂
Awesome article. I’m really impressed by the benchmarks, especially for box-intersect. I am wondering though to what extent something like box-intersect can be used as a heuristic for doing collision detection on objects that may or may not be boxes. Suppose you had a scene with an arbitrary number of shapes of arbitrary types (some are boxes, some are balls, and some are convex polygons). At what point does it become interesting to bound the shapes that aren’t boxes by a minimum bounding box, and then if the bounding boxes collide then apply an appropriate algorithm for those shapes?
This is something which I have wondered about, and don’t really have any good answers for. What I can say though is that in practice it seems to be a common strategy. Many physics engines and CAD kernels use boxes as their bounding primitives (for example Box2D, Bullet, etc.), so I think that there is at least some evidence that it works. However, I still haven’t seen a more rigorous analysis of this strategy, especially for 3D shapes.
That’s interesting. I think that it is an avenue worth exploring. Given that now issues like battery usage have started to become a concern, I think it’s necessary to explore more aggressive heuristics and strategies to try to do as little computation as possible while still being able to simulate as much as possible. I hope you don’t mind if I tinker with box-intersect while I explore trying to apply it to do collision detection on more complex shapes.
Here is an algorithm that can doing collision detection on raster objects with arbitrary shapes: https://github.com/guo-yong-zhi/Stuffing.jl
Wow, great article! Nice work. And thank you for the compliments regarding p2.js and cannon.js!
I know you already mentioned it, but I want to stress it even more: the sweep and prune (SAP ) algorithm in p2, cannon, Bullet and other rigid body simulators are only efficient in the warm start case. It’s ideal for simulations longer than one time step, especially if the characteristic velocity is small.
Hello,
Very interesting article, thanks for writing it!
If I understood correctly, the problem was to report all pair-wise rectangle-rectangle intersections, correct? May I ask you about a different problem, namely for given a rectangular window report all rectangles overlapped by it, what algorithm/data structure/library would you suggest?
Thanks once more!
Is there a broad name for the box-intersect algorithm? I’m attempting to do some research on it however it seems to be very sparse.
Thanks for a great readd