The last post I wrote on Minecraft-like engines got a lot of attention, and so I figured it might be interesting to write a follow up. This time I’ll try to tackle a different problem:
Meshing
One of the main innovations in Infiniminer (and Minecraft) is that they use polygons instead of raycasting to render their volumes. The main challenge in using polygons is figuring out how to convert the voxels into polygons efficiently. This process is called meshing, and in this post I’m going to discuss three different algorithms for solving this problem. But before doing this, we first need to say a bit more precisely what exactly meshing is (in the context of Minecraft maps) and what it means to do meshing well. For the sake of exposition, we’ll consider meshing in a very simplified setting:
- Instead of having multiple block types with different textures and lighting conditions, we’ll suppose that our world is just a binary 0-1 voxel map.
- Similarly we won’t make any assumptions about the position of the camera, nor will we consider any level of detail type optimizations.
- Finally, we shall suppose that our chunks are stored naively in a flat bitmap (array).
I hope you are convinced that making these assumptions does not appreciably change the core of the meshing problem (and if not, well I’ll try to sketch out in the conclusion how the naive version of these algorithms could be extended to handle these special cases.)
In a typical Minecraft game chunks do not get modified that often compared to how frequently they are drawn. As a result, it is quite sensible to cache the results from a mesher and only ever call it when the geometry changes. Thus, over the lifetime of a mesh, the total amount of computational work it consumes is asymptotically dominated by the cost of rendering.
Recall that at a high level polygon rendering breaks down into two parts: 1.) primitive assembly, and 2.) scan conversion (aka polygon filling). In general, there really isn’t any way to change the number of pixels/fragments which need to be drawn without changing either the resolution, framerate or scene geometry; and so for the purposes of rendering we can regard this as a fixed cost (this is our second assumption). That leaves primitive assembly, and the cost of this operation is strictly a function of the number of faces and vertices in the mesh. The only way this cost can be reduced is by reducing the total number of polygons in the mesh, and so we make the following blanket statement about Minecraft meshes:
Criteria 1: Smaller meshes are better meshes.
Of course, the above analysis is at least a little naive. While it is true that chunk updates are rare, when they do happen we would like to respond to them quickly. It would be unacceptable to wait for more than a frame or two to update the displayed geometry in response to some user change. Therefore, we come to our second (and final) criteria for assessing mesh algorithms:
Criteria 2: The latency of meshing cannot be too high.
Speed vs. Quality
Intuitively, it seems like there should be some tradeoff here. One could imagine a super-mesher that does a big brute force search for the best mesh compared to a faster, but dumber method that generates a suboptimal mesh. Supposing that we were given two such algorithms, it is not a-priori clear which method we should prefer. Over the long term, maybe we would end up getting a better FPS with the sophisticated method, while in the short term the dumb algorithm might be more responsive (but we’d pay for it down the road).
Fortunately, there is a simple solution to this impasse. If we have a fast, but dumb, mesher; we can just run that on any meshes that have changed recently, and mark the geometry that changed for remeshing later on. Then, when we have some idle cycles (or alternatively in another thread) we can run the better mesher on them at some later point. Once the high quality mesh is built, the low quality mesh can then be replaced. In this way, one could conceivably achieve the best of both worlds.
Some Meshing Algorithms
The conclusion of this digression is that of the two of these criteria, it is item 1 which is ultimately the most important (and unfortunately also the most difficult) to address. Thus our main focus in the analysis of meshing algorithms will be on how many quads they spit out. So with the preliminaries settles, let’s investigate some possible approaches:
The Stupid Method:
The absolute dumbest way to generate a Minecraft mesh is to just iterate over each voxel and generate one 6-sided cube per solid voxel. For example, here is the mesh you would get using this approach on a 8x8x8 solid region:
 The time complexity of this method is linear in the number of voxels. Similarly, the number of quads used is 6 * number of filled voxels. For example, in this case the number of quads in the mesh is 8*8*8*6 = 3072. Clearly this is pretty terrible, and not something you would ever want to do. In a moment, we’ll see several easy ways to improve on this, though it is perhaps worth noting that for suitably small geometries it can actually be workable.
The time complexity of this method is linear in the number of voxels. Similarly, the number of quads used is 6 * number of filled voxels. For example, in this case the number of quads in the mesh is 8*8*8*6 = 3072. Clearly this is pretty terrible, and not something you would ever want to do. In a moment, we’ll see several easy ways to improve on this, though it is perhaps worth noting that for suitably small geometries it can actually be workable.
The only thing good about this approach is that it is almost impossible to screw up. For example, I was able to code it up correctly in minutes and it worked the first time (compared to the culling method which took me a few iterations to get the edge cases right.) Even if you don’t plan on using this approach it can still be handy to have it around as a reference implementation for debugging other algorithms.
Culling:
Clearly the above method is pretty bad. One obvious improvement is to just cull out the interior faces, leaving only quads on the surface. For example, here is the mesh you get from culling the same 8x8x8 solid cube:

Practically speaking, this method is pretty much the same as the previous, except we have to do a bit of extra book keeping when we traverse the volume. The reason for this is that now we not only have to read each voxel, but we we also have to scan through their neighbors. This requires a little more thought when coding, but time complexity-wise the cost of generating this mesh is asymptotically the same as before. The real improvement comes in the reduction of quads. Unlike the stupid method, which generates a number of quads proportional to the boundary, culling produces quads proportional to the surface area. In this case, the total number of faces generated is 8*8*6 = 384 — a factor of 8x better!
It is not hard to see that the culled mesh is strictly smaller than the stupid mesh (and often by quite a lot!). We can try to estimate how much smaller using a dimensional analysis argument: assuming that our geometry is more-or-less spherical, let  be its radius. Then, in the stupid method we would expect to generate about
be its radius. Then, in the stupid method we would expect to generate about 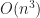 quads, while in the culled version we’d get only
quads, while in the culled version we’d get only 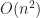 . This gives an improvement of a factor of about
. This gives an improvement of a factor of about  , which is pretty good! So, if our chunks were say 16x16x16, then we might expect the culled volume to have about 16x fewer faces than the naive method (heuristically). Of course, spherical geometry is in some sense the best possible case. If your world is really jagged and has lots of holes, you wouldn’t expect much improvement at all. In the worst case (namely a checkerboard world) the size of the meshes produced would be identical! In practice, one would usually expect something somewhere in between.
, which is pretty good! So, if our chunks were say 16x16x16, then we might expect the culled volume to have about 16x fewer faces than the naive method (heuristically). Of course, spherical geometry is in some sense the best possible case. If your world is really jagged and has lots of holes, you wouldn’t expect much improvement at all. In the worst case (namely a checkerboard world) the size of the meshes produced would be identical! In practice, one would usually expect something somewhere in between.
Greedy Meshing:
The previous two approaches are probably the most frequently cited methods for generating Minecraft-like meshes, but they are quite far from optimal. The last method that I will talk about today is a greedy algorithm which merges adjacent quads together into larger regions to reduce the total size of the geometry. For example, we could try to mesh the previous cube by fusing all the faces along each side together:

This gives a mesh with only 6 quads (which is actually optimal in this case!) Clearly this improvement by a factor of 64 is quite significant. To explain how this works, we need to use two ideas. First, observe that that it suffices to consider only the problem of generating a quad mesh for some 2D cross section. That is we can just sweep the volume across once in each direction and mesh each cross section separately:

This reduces the 3D problem to 2D. The next step (and the hard one!) is to figure out how to mesh each of these 2D slices. Doing this optimally (that is with the fewest quads) is quite hard. So instead, let’s reformulate the problem as a different type of optimization. The idea is that we are going to define some type of total order on the set of all possible quadrangulations, and then pick the minimal element of this set as our mesh. To do this, we will first define an order on each quad, which we will then extend to an order on the set of all meshes. One simple way to order two quads is to sort them top-to-bottom, left-to-right and then compare by their length.
More formally, let’s denote a quad by a tuple  , where
, where 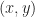 is the upper left corner and
is the upper left corner and 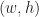 is the width / height of the quad. Given such a representation of a quad, we denote its underlying set by:
is the width / height of the quad. Given such a representation of a quad, we denote its underlying set by:
![Q_{x,y,w,h} = \{ (s,t) \in \mathbb{R}^2 : x \leq s \leq x + w \: \mathrm{ and } \: y \leq t \leq y+h \} = [x,x+w] \times [y,y+h]](https://s0.wp.com/latex.php?latex=Q_%7Bx%2Cy%2Cw%2Ch%7D+%3D+%5C%7B+%28s%2Ct%29+%5Cin+%5Cmathbb%7BR%7D%5E2+%3A+x+%5Cleq+s+%5Cleq+x+%2B+w+%5C%3A+%5Cmathrm%7B+and+%7D+%5C%3A+y+%5Cleq+t+%5Cleq+y%2Bh+%5C%7D+%3D+%5Bx%2Cx%2Bw%5D+%5Ctimes+%5By%2Cy%2Bh%5D+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
By a 2D quad mesh, here we mean a partition of some set  into a collection of quads
into a collection of quads 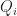 . Now let’s define a total order on these quads, given
. Now let’s define a total order on these quads, given 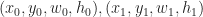 define the relation:
define the relation:
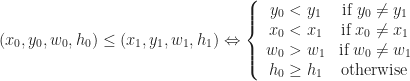
Or if you prefer to read psuedocode, we could write it like this:
compareQuads( (x0, y0, w0, h0), (x1, y1, w1, h1) ):
if ( y0 != y1 ) return y0 < y1
if ( x0 != x1 ) return x0 < x1
if ( w0 != w1 ) return w0 > w1
return h0 >= h1
Exercise: Check that this is in fact a total order.
The next thing we want to do is extend this ordering on quads to an ordering on meshes, and we do this in a very simple way. Given two sorted sequences of quads 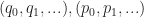 such that
such that 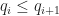 and and
and and 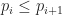 , we can simply compare them lexicographically. Again, this new ordering is in fact a total order, and this means that it has a unique least element. In greedy meshing, we are going to take this least element as our mesh, which we’ll call the greedy mesh. Here is an example of what one of these lexicographically minimal meshes looks like:
, we can simply compare them lexicographically. Again, this new ordering is in fact a total order, and this means that it has a unique least element. In greedy meshing, we are going to take this least element as our mesh, which we’ll call the greedy mesh. Here is an example of what one of these lexicographically minimal meshes looks like:

You may be skeptical that finding the least element in this new order always produces a better quad mesh. For example, there is no guarantee that the least element in this new order is also the mesh with the fewest quads. Consider what you might get when quad meshing a T-shape using this method:

Exercise 2: Find a mesh of this shape which uses fewer quads.
However, we can say a few things. For example, it always true that each quad in the greedy mesh completely covers at least one edge on the perimeter of the region. Therefore, we can prove the following:
Proposition: The number of quads in the greedy mesh is strictly less than the number of edges in the perimter of the region.
This means that in the worst case, we should expect the size of the greedy mesh to be roughly proportional to the number of edges. By a heuristic/dimensional analysis, it would be reasonable to estimate that the greedy mesh is typically about  times smaller than the culled mesh for spherical geometries (where is the radius of the sphere as before). But we can be more precise about how good the greedy mesh actually is:
times smaller than the culled mesh for spherical geometries (where is the radius of the sphere as before). But we can be more precise about how good the greedy mesh actually is:
Theorem: The greedy mesh has no more than 8x as many quads than the optimal mesh.
That’s within a constant factor of optimality! To prove this, we’ll need to introduce a bit of nomenclature first. We’ll call a vertex on the perimeter of a region convex if it turns to the right when walking around the mesh clockwise, and otherwise we’ll call it concave. Here is a picture, with the convex vertices colored in red and the concave vertices colored in green:

There’s a neat fact about these numbers. It turns out that if you sum them up, you always get the same thing:
Proposition: For any simply connected region with 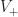 convex and
convex and 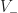 concave vertices on the perimeter,
concave vertices on the perimeter, 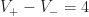 .
.
This can be proven using the winding number theorem from calculus. But we’re going to apply this theorem to get a lower bound on the number of quads in an arbitrary mesh:
Lemma: Any connected genus  region with a perimeter of
region with a perimeter of 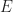 edges requires at least
edges requires at least 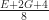 quads to mesh.
quads to mesh.
Proof: Let  denote the number of convex/concave vertices on the perimeter respectively. Because each quad can cover at most 4 convex vertices, the number of quads,
denote the number of convex/concave vertices on the perimeter respectively. Because each quad can cover at most 4 convex vertices, the number of quads,  , in the mesh is always at least
, in the mesh is always at least  . By the winding number theorem, it is true that for simply connected regions
. By the winding number theorem, it is true that for simply connected regions 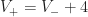 , and so
, and so 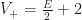 . Therefore any mesh of a simply connected region requires at least
. Therefore any mesh of a simply connected region requires at least 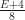 quads. To extend this to non-simply connected regions, we observe that any quad mesh can be cut into a simply connected one by slicing along some edges in the quad mesh connecting out to the boundary. Making this cut requires introducing at most two edges per each hole in the object, and so we could just as well treat this as a simply connected region having
quads. To extend this to non-simply connected regions, we observe that any quad mesh can be cut into a simply connected one by slicing along some edges in the quad mesh connecting out to the boundary. Making this cut requires introducing at most two edges per each hole in the object, and so we could just as well treat this as a simply connected region having 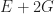 edges, and applying the previous result gives us the bound in the lemma.
edges, and applying the previous result gives us the bound in the lemma. 
To prove our main theorem, we just combine these two lemmas together, using the fact that 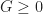 . In summary, we have the following progression:
. In summary, we have the following progression:
Optimal 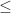 Greedy Culled Stupid
Greedy Culled Stupid
So now that I’ve hopefully convinced you that there are some good theoretical reasons why greedy meshing outperforms more naive methods, I’ll try to say a few words about how you would go about implementing it. The idea (as in all greedy algorithms) is to grow the mesh by making locally optimal decisions. To do this, we start from an empty mesh and the find the quad which comes lexicographically first. Once we’ve located this, we remove it from the region and continue. When the region is empty, we’re done! The complexity of this method is again linear in the size of the volume, though in practice it is a bit more expensive since we end up doing multiple passes. If you are the type who understands code better than prose, you can take a look at this javascript implementation which goes through all the details.
Demo and Experiments
To try out some of these different methods, I put together a quick little three.js demo that you can run in your browser:
Click here to try out the Javascript demo!
Here are some pictures comparing naive meshing with the greedy alternative:


Naive (left), 690 quads vs. Greedy (right), 22 quads


4770 quads vs. 2100 quads
.

2198 quads vs. 1670 quads
As you can see, greedy meshing strictly outperforms naive meshing despite taking asymptotically the same amount of time. However, the performance gets worse as the curvature and number of components of the data increase. This is because the number of edges in each slice increases. In the extreme case, for a collection of disconnected singleton cubes, they are identical (and optimal).
Conclusion and some conjectures:
Well, that’s it for now. Of course this is only the simplest version of meshing in a Minecraft game, and in practice you’d want to deal with textures, ambient occlusion and so on (which adds a lot of coding headaches, but not much which is too surprising). Also I would ask the reader to excuse the fairly rough complexity analysis here. I’d actually conjecture that the true approximation factor for the greedy algorithm much less than 8, but I’ve spent enough time writing this post so I guess I’ll just leave it as is for now. I think the real weakness in my analysis lies in the computation of the upper bound on the size of greedy mesh. I’d actually guess the following is true:
Conjecture: The size of the greedy mesh is at most 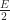 .
.
If this conjecture holds true, then it would reduce the current bounds on the approximation factor to 4x instead of 8x. It’s also not clear that this is the best known greedy approximation. I’d be interested to learn how Minecraft and other voxel engines out there solve this problem. From my time playing the game, I got the impression that Minecraft was doing some form of mesh optimization beyond naive culling, though it was not clear to me exactly what was going on (maybe they’re already doing some form greedy meshing?)
It is also worth pointing out that the time complexity of each of these algorithms is optimal (ie linear) for a voxel world which is encoded as a bitmap. However, it would be interesting to investigate using some other type of data structure. In the previous post, I talked about using run-length encoding as an alternative in-memory storage of voxels. But greedy meshing seems to suggest that we could do much better: why not store the voxels themselves as a 3D cuboid mesh? Doing this could drastically reduce the amount of memory, and it is plausible that such a representation could also be used to speed up meshing substantially. Of course the additional complexity associated with implementing something like this is likely to be quite high. I’ll now end this blog post with the following open problem:
Open Problem: Do there exist efficient data structures for dynamically maintaining greedy meshes?
If you have other questions or comments, please post a response or send me an email!
Errata
6/30/12: Corrected an error in the definition of the order on each quad. Was written (x,y,w,h) when it should have been (y,x,w,h) (Thanks Matt!)



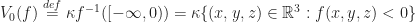

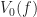
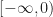
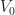
![Z_0(f) \stackrel{def}{=} f^{-1}( [-\infty, 0] ) = \{ (x,y,z) \in \mathbb{R}^3 : f(x,y,z) \leq 0 \}](https://s0.wp.com/latex.php?latex=Z_0%28f%29+%5Cstackrel%7Bdef%7D%7B%3D%7D+f%5E%7B-1%7D%28+%5B-%5Cinfty%2C+0%5D+%29+%3D+%5C%7B+%28x%2Cy%2Cz%29+%5Cin+%5Cmathbb%7BR%7D%5E3+%3A+f%28x%2Cy%2Cz%29+%5Cleq+0+%5C%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
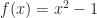
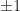


![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
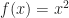

is not necessarily a solid. This means that it is not always uniquely determined by its boundary, and that certain mass properties (like volume, inertia, momentum, etc.) may fail to be well defined. On the other hand,
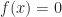
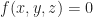
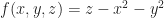
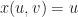
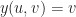

![\varphi : [0,1] \to \mathbb{R}^3](https://s0.wp.com/latex.php?latex=%5Cvarphi+%3A+%5B0%2C1%5D+%5Cto+%5Cmathbb%7BR%7D%5E3&bg=ffffff&fg=1a1a1a&s=0&c=20201002)

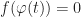
by sampling
.



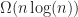 operations to perform a monotone subdivision, where
operations to perform a monotone subdivision, where 








 .
.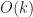 measures the algorithm dependent overhead which is determined by the complexity of the surface and the type of mesh generation. Since it is mesh generation that we want to study, ideally we’d like to keep
measures the algorithm dependent overhead which is determined by the complexity of the surface and the type of mesh generation. Since it is mesh generation that we want to study, ideally we’d like to keep 
 .
. increases, the number of chambers increases as well, along with the surface area. This gives us a pretty good way to control for the complexity of surfaces in an experiment. I implemented this idea in a
increases, the number of chambers increases as well, along with the surface area. This gives us a pretty good way to control for the complexity of surfaces in an experiment. I implemented this idea in a 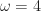 ). Garbage collection costs are amortized by repeated runs (10 in this case). All experiments were performed on a 65x65x65 volume with
). Garbage collection costs are amortized by repeated runs (10 in this case). All experiments were performed on a 65x65x65 volume with 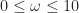 .
.
















 ,
,
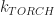 ,
,
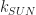
 , or cubically for a world with unlimited z-value.
, or cubically for a world with unlimited z-value.
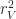
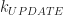

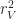
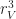 if you have unlimited height. So, if you believe these estimates are reasonable, then you should be convinced that iteration by far dominates the performance of a Minecraft style game. In fact, this estimate explains a few other things, like why visible radius is such an important performance factor in Minecraft. Increasing the draw radius linearly, degrades the performance quadratically!
if you have unlimited height. So, if you believe these estimates are reasonable, then you should be convinced that iteration by far dominates the performance of a Minecraft style game. In fact, this estimate explains a few other things, like why visible radius is such an important performance factor in Minecraft. Increasing the draw radius linearly, degrades the performance quadratically! be the set of block types, and let
be the set of block types, and let  be a map representing our world (ie an assignment of block types to integral coordinates on a regular grid). A radius
be a map representing our world (ie an assignment of block types to integral coordinates on a regular grid). A radius  -Moore neighborhood is an element of the set
-Moore neighborhood is an element of the set  . The Moore neighborhood of a coordinate
. The Moore neighborhood of a coordinate 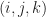 in
in 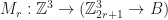 such that,
such that,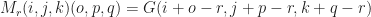
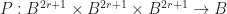 , and the application of
, and the application of 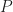 to
to 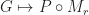



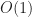

 is the number of occupied (virtual) chunks
is the number of occupied (virtual) chunks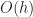
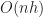
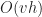
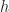 is the height of the octree
is the height of the octree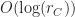
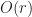

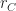 is the number of runs a single chunk.
is the number of runs a single chunk.
 entry corresponds to the coefficient for the degree i monomial. Naively generalizing a bit, the same idea works for multivariate polynomials as well, where you simply make the array multidimensional. For example, suppose you had the 2D coefficient matrix:
entry corresponds to the coefficient for the degree i monomial. Naively generalizing a bit, the same idea works for multivariate polynomials as well, where you simply make the array multidimensional. For example, suppose you had the 2D coefficient matrix: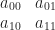

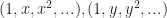 and the then plug them into the coefficient tensor using ordinary Einstein summation.
and the then plug them into the coefficient tensor using ordinary Einstein summation.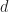 variables with a maximum per-coefficient degree of
variables with a maximum per-coefficient degree of 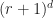 scalars worth of memory. However, this representation scheme does have some major problems:
scalars worth of memory. However, this representation scheme does have some major problems: from the above example, it is actually second order, and so is the polynomial that it represents. However, we are missing the extra terms for
from the above example, it is actually second order, and so is the polynomial that it represents. However, we are missing the extra terms for  .
. , that
, that  , and thus we would need to resize the matrix to keep up with the extra stuff.
, and thus we would need to resize the matrix to keep up with the extra stuff.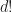 .
. .
.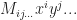 is not multilinear. As we saw last time it can be useful to deal with multivariate polynomials using tensors. Similarly, it is also useful to split them up into homogeneous parts (that is grouping all the terms which have the same degree together). We also showed how this approach greatly simplified the expression of a general multidimensional Taylor series expansion. So today, we are going to investigate a different, and more “tensor-flavored” method for representing homogeneous polynomials.
is not multilinear. As we saw last time it can be useful to deal with multivariate polynomials using tensors. Similarly, it is also useful to split them up into homogeneous parts (that is grouping all the terms which have the same degree together). We also showed how this approach greatly simplified the expression of a general multidimensional Taylor series expansion. So today, we are going to investigate a different, and more “tensor-flavored” method for representing homogeneous polynomials. , with degree r is a polynomial,
, with degree r is a polynomial,
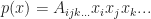
 is multilinear if for any of its arguments
is multilinear if for any of its arguments  , it is a linear function, that is:
, it is a linear function, that is:
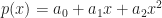
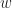 , and construct the new polynomial:
, and construct the new polynomial: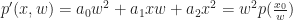
 is a homogeneous polynomial of degree 2.
is a homogeneous polynomial of degree 2. , then
, then  .
. of degree r in d unknowns. Then we add a variable, w, and construct the new homogeneous degree r polynomial,
of degree r in d unknowns. Then we add a variable, w, and construct the new homogeneous degree r polynomial,
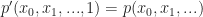 .
.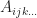 is called symmetric if for all permutations of an index,
is called symmetric if for all permutations of an index,  and so on,
and so on, 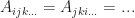 .
. .
. (and so on).
(and so on). .
. where
where 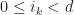 for all
for all 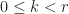 .
. where
where  for all k, and
for all k, and  .
.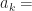 the number of elements in
the number of elements in 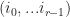 that are equal to k
that are equal to k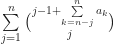
 , and suppose that you are allowed the following two operations:
, and suppose that you are allowed the following two operations:
 and so on
and so on ., and then we can evaluate some approximation of f by summing up the first k terms in the above approximation:
., and then we can evaluate some approximation of f by summing up the first k terms in the above approximation:

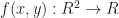 is a 2D scalar-valued function. Then, let us look for a best quadratic (aka degree 2) approximation to f within the region near
is a 2D scalar-valued function. Then, let us look for a best quadratic (aka degree 2) approximation to f within the region near 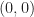 . By analogy to the 1D case, we want to find some 2nd order polynomial $p(x,y)$ in two variables such that:
. By analogy to the 1D case, we want to find some 2nd order polynomial $p(x,y)$ in two variables such that: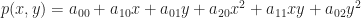
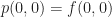


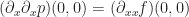



 is determined by the equation,
is determined by the equation,

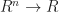 (via the dot-product), a tensor can represents a multi-linear function,
(via the dot-product), a tensor can represents a multi-linear function,  : that is, it takes in several vectors and spits out a scalar which varies linearly in each of its arguments.
: that is, it takes in several vectors and spits out a scalar which varies linearly in each of its arguments.
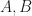 with dimensions
with dimensions 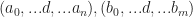 and ranks n,m respectively and some index between them with a common dimension. Then we can form a new tensor with rank n + m – 1 by summing over that index in A and B simultaneously:
and ranks n,m respectively and some index between them with a common dimension. Then we can form a new tensor with rank n + m – 1 by summing over that index in A and B simultaneously:
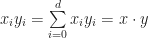



 with respect to the
with respect to the  . Combined with Einstein’s notation, we can also perform operations such as taking a gradient of a function along a certain direction. If
. Combined with Einstein’s notation, we can also perform operations such as taking a gradient of a function along a certain direction. If  is,
is,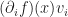
 whose components are just the usual
whose components are just the usual  coordinate variables, and pick some rank 1 tensor A with appropriate dimension. If we just plug in x, then we get the following expression:
coordinate variables, and pick some rank 1 tensor A with appropriate dimension. If we just plug in x, then we get the following expression: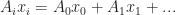


 are really the same and so we really don’t need to store both the coefficients
are really the same and so we really don’t need to store both the coefficients 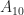 and
and  . We could make our lives a bit easier if we just assumed that they were equal. In fact, it would be really nice if whenever we took any index, like say
. We could make our lives a bit easier if we just assumed that they were equal. In fact, it would be really nice if whenever we took any index, like say  and then permuted it to something arbitrary, for example
and then permuted it to something arbitrary, for example  , it always gave us back the same thing. To see why this is, let us try to work out what the coefficient for the monomial
, it always gave us back the same thing. To see why this is, let us try to work out what the coefficient for the monomial  in the degree n polynomial given by
in the degree n polynomial given by  . Directly expanding using Einstein summation, we get a sum over all permutations of the indices
. Directly expanding using Einstein summation, we get a sum over all permutations of the indices  :
: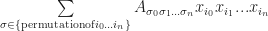
 coefficients are identical, then that above nasty summation has a pretty simple form: namely it is a
coefficients are identical, then that above nasty summation has a pretty simple form: namely it is a  in $A_{i j k} x_i x_j x_k$, then we could just use the following simple formula:
in $A_{i j k} x_i x_j x_k$, then we could just use the following simple formula:
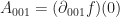 , then the above formula is almost exactly the right formula for the Taylor series coefficient of
, then the above formula is almost exactly the right formula for the Taylor series coefficient of 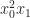 in the expansion of
in the expansion of  , but no matter, we can just divide that off. Taking this into account, we get the following striking formula for the Taylor series expansion of a function
, but no matter, we can just divide that off. Taking this into account, we get the following striking formula for the Taylor series expansion of a function 
